This is a note taken in Chinese for my data science course Advanced Big Data Analytics.
Our course includes the following parts: Linux Command, Spark, Operating System (includes concepts about both cpu and process), and GPU.
Linux 文件系统
文件系统的定义
- 文件系统是有组织存储文件或数据的方法,目的是易于查询和存取。
基本概念
- 存储介质:硬盘、光盘等
- 硬盘的分割:对于大硬盘,需要合理规划分区。
- 文件系统的创建:又名格式化,通过一些初始化工具来进行。
- 文件系统的挂载(mount):文件系统只有挂载后才能使用,挂载时要有挂载点,通常是一个空置的目录。
常见的文件系统及其结构
Linux文件系统结构
目录结构
-
目录树,父子关系(树状结构、父子结构
-
Linux与WIndows的区别:
- Windows以分区为树根,多个分区则多个树并列

- Linux所有文件系统都在一个树根上,进行分区时先划分根分区,再将其他分区挂载到该根目录下

-
以根目录“/”为起点,向下展开
-

-
关于当前工作目录
pwd查看当前目录,cd切换目录.表示当前目录,..表示当前目录的父目录,-表示用cd切换目录之前你所在的目录,~表示主目录的绝对路径
Path 路径
- 绝对路径、相对路径
- 不以
/和~开始的路径均为相对路径
File 文件类型
- 普通文件、目录文件、链接文件、设备文件
- 普通文件:压缩与归档文件、文字与多媒体文件、编程与脚本文件、系统文件
- 链接文件:作用类似于“快捷方式”,本身不包含内容,指向其他文件或目录
- 设备文件:放在
/dev目录下 cmd line- 以
.开头的文件为隐藏文件 - 用
file file_name查看文件类型 ln创建链接文件
- 以
Chmod 文件的访问权限
-
三种方式限制访问权限:
- 只允许用户自己访问
- 允许一个预先指定的用户组的用户访问
- 允许系统内所有用户访问
-
三种权限:读、写、执行
- 创建文件或目录的所有者自动拥有读和写的权限
- 文件或目录可以被三种类型用户访问:所有者、同组用户、其他用户
-
查看文件的访问权限
ls -l查看文件和目录的属性-

- 文件类型:
-为普通文件,d为目录,l为链接文件,b/c/s/p等很少见,碰见再查 - 文件权限:所有者权限(3)/同组用户权限(3)/其他用户权限(3)
r为读(包括阅读文件,浏览目录内容)w为写(包括修改文件,移动、删除目录内文件)x为执行(包括执行文件,进入目录)-为不具有该权限- 例子:每个用户自己的专属目录(主目录)通常放置在
/home下,默认权限通常为rwx------
-
修改访问权限
chmod用于更改已有文件或目录的访问权限- 两种用法
- 文字设定法
chmod [who][+|-|=][mode] file_name- 操作对象
[who]=u/g/o/a- u代表user,g代表group,o代表others,a代表all
- 没有指定who则缺省值为a
- 操作符号
[+|-|=]- +代表添加权限,-代表取消权限,=赋予给定权限并取消其他所有权限
- 访问权限
[mode]=r/w/x- r代表可读,w代表可写,x代表可执行
- 注意:一个命令行中给出多个权限方式时用逗号隔开
e.g. chmod g+r,o+w file_name
- 数字设定法
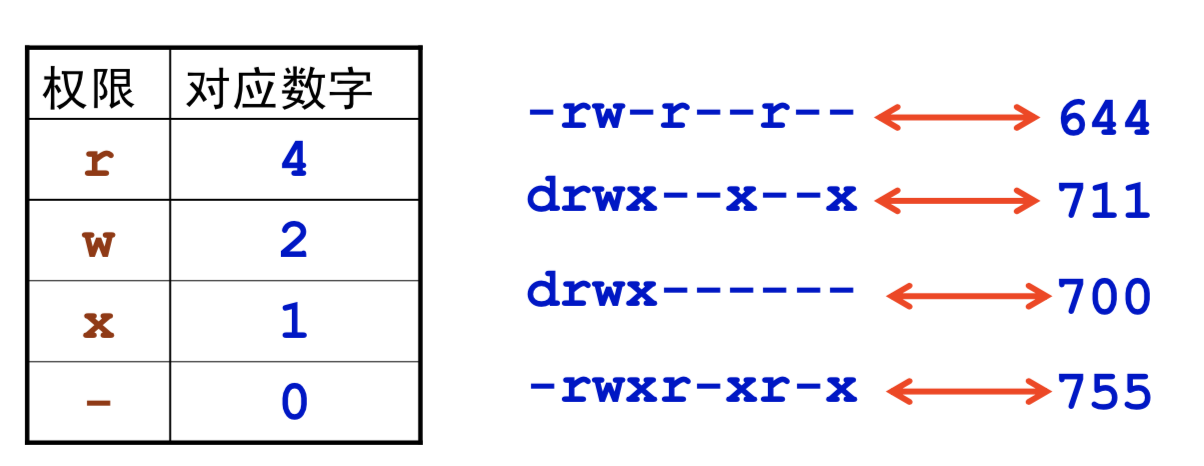
e.g. chmod 644 file_name
- 文字设定法
umask- 创建新文件或目录时系统指定的缺省访问权限由
umask值决定 
- 创建新文件或目录时系统指定的缺省访问权限由
Mount 挂载
mount挂载文件系统,umount卸载文件系统
处理文件与目录的一些基本命令
df -h查看磁盘使用情况以及文件系统被挂载的位置du -sh file_name查看指定文件或目录的大小uname -a查看系统内核版本cut -c n1-n2 file_name显示每行从开头算起第n1到n2个字符fdisk -l进行分区wc -c/w/l file_name统计文件字节数/字数/行数head -20 file_name查看文件开头20行tail -20/f file_name查看文件末尾20行/实时动态查看最后10行(常用于追踪日志文件
Linux Shell
shell的定义及一些常见shell
==shell所扮演的角色==
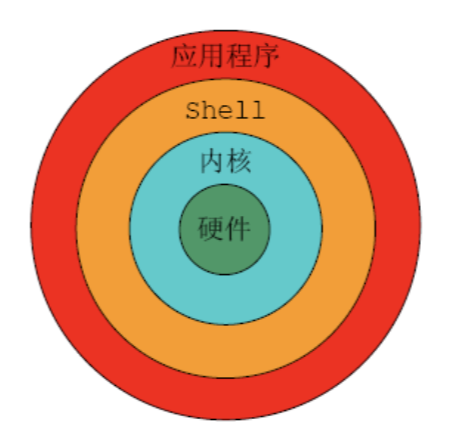
- 用户界面:提供用户与Linux内核进行交互的接口,
cmd line的每个命令都由shell先解释再传给内核执行 - 命令语言解释器:内建shell命令集,shell也可被其他app所调用
- 程序设计语言:支持循环/函数/变量和数组,任何
cmd line中能键入的命令都能放到一个可执行shell程序里。
常用的shell
- Bourne Shell, C shell, Korn shell
- 扩展:tcsh(from csh), Bourne Again shell(from bash, sh), Public Domain Korn shel(from pdksh, ksh)
- Bash是大多数Linux系统的缺省shell
bash的基本功能(通配符、别名等)
==Command Line 命令行==
-
command [选项][参数]- 选项先于参数
e.g. ls -l /home/jypan/linux/
- 选项先于参数
-
分号隔开一个命令行中的多个命令
e.g. ls -F; cp -i mydata newdata-
若命令太长可以用
\来续行,大多数shell再达到行尾时会自动断开长命令 -
ls -F; \ cp -i mydata newdata
-
-
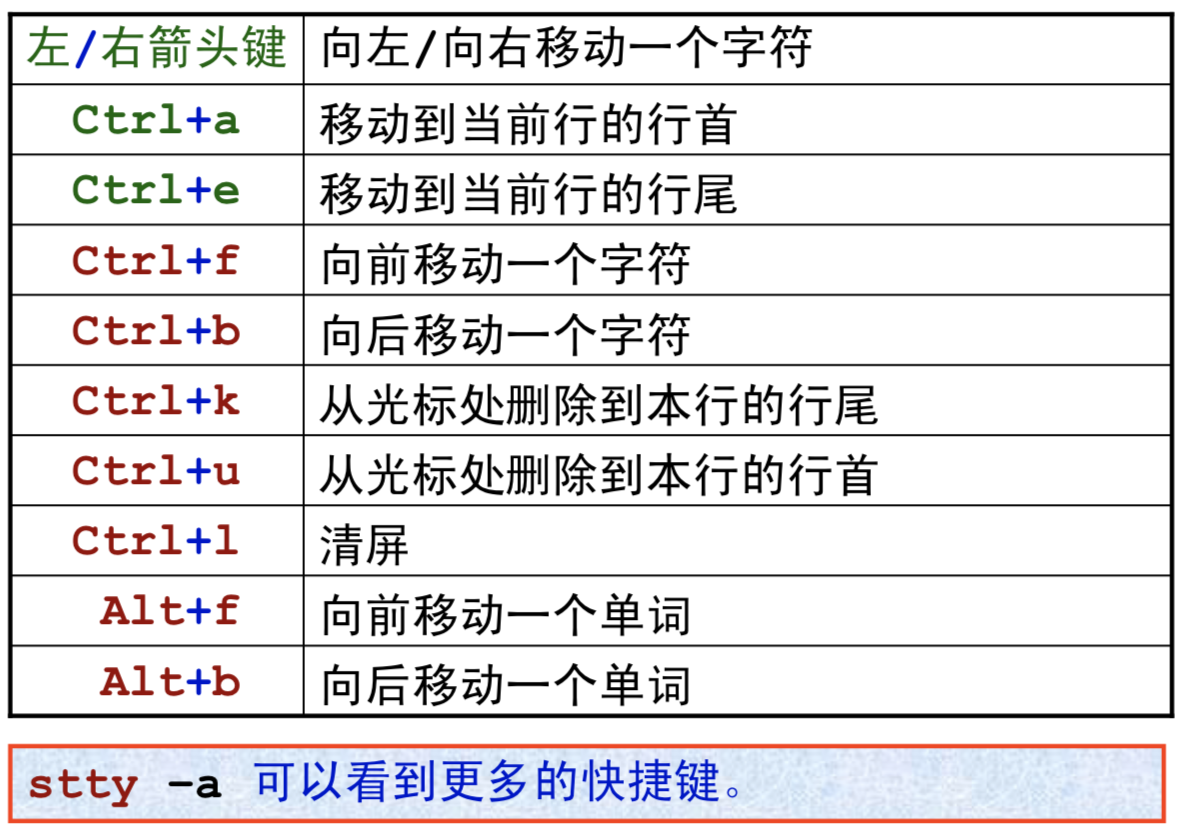
命令行编辑
Pattern与通配符
- 定义:简化命令书写的特殊字符
- 模式串:用通配符指定的一种模式,shell将会把能够与这种模式匹配的文件作为输入文件
- 三种通配符
*/?/[]
- 注意:
*最常用的方法是查找具有相同扩展名的文件 `e.g.ls *.tar.gz?匹配任何单个字符,常用来查找比*更为精确的匹配[]只匹配一个字符,可在其中使用-来指定范围,如[a-zA-Z]*[0-9]代表以字母开头数字结尾的所有文件!起到反意作用-若在方括号外面则为普通字符,仅在[]内有效,而*和?在[]外为通配符,若在方括号内则为普通字符- 文件名最前面的
.和路径名中的/必须显示匹配,.*才能匹配.bashrc
Alias 别名
alias lf='ls -F'创建别名e.g. alias ggg="git add .; git commit -m \"automatic upload\"; git push"用ggg代替github上传命令- 注意:等号两边不能有空格
unalias lf取消别名- 注意:别名只是在当前shell中一直有效
- 若要一直使用某些别名,可以在bash启动脚本中添加设置别名的命令,这样每次打开一个(虚拟)终端时系统就会自动设置别名
alias查看已创建的别名
Tab 命令行自动补齐
his<Tab>补全为history查看用户命令历史
==Pipe 管道==
- 含义:将前一个命令的输出作为后一个命令的输入
e.g. ls /local | du -sh * - 管道举例:

==Redir 重定向==
- 三种数据流:标准输入(STDIN)、标准输出(STDOUT)、标准错误(STDERR)
<输入重定向:将文件中的内容作为命令的输入>输出重定向:将命令的输出保存到一个文件中- 如果输出文件已经存在,则原文件中的内容将被删除
- 使用
>>可以将重定向输出的内容添加到原文件后面,类似于append模式
His 命令历史记录
history 30查看最近的30个命令历史fc -l 30 50列出历史记录中第30到第50之间的命令上下箭头键:在命令历史记录中移动- 感叹号的用法:
!!执行最近一次使用的命令!n:n为数字,执行命令历史记录中的第n个命令!s:s是字符串,执行命令历史记录中的以该字符串开头的最近一个命令
引用
- 三种引用方式:
- 使用转义字符
\ - 使用单引号
''- 单引号中的字符都将作为普通字符,且不允许出现另外的单引号
- 使用双引号
""- 双引号中部分字符保留特殊含义:
$、\、'、"、\n
- 双引号中部分字符保留特殊含义:
- 使用转义字符
特殊字符

==shell变量==
- 三类变量:
- 内部变量:系统提供,用户不能修改
- 用户变量:用户建立和修改,shell脚本中常用
- 环境变量:不需要定义即可直接在shell中使用,某些变量可修改
echo ${var_name}查询变量值env查询shell中的环境变量
定制bash
- 命令提示符:一级提示符
$,二级提示符>export PS1="\t\w\$"重设一级提示符
- ==bash配置文件==
- 启动交互式会话过程出现一级提示符
$前,系统会读取几个配置文件并执行这些文件中的命令。 - 用处:设置shell变量值或建立别名等。
- bash配置文件:
/etc/profile为全局bash启动脚本,用于设置标准bash环境~/.bash_profile和~/.bash_login和~/.profile将被顺序查找并执行第一个找到的文件,在这些文件中,用户可以定义自己的环境变量,并且可以覆盖/etc/profile中定义的设置。~/.bashrc将在bash启动后读入并执行该文件中所有内容- 通常个人bash环境设置都定义在其中
- 启动交互式会话过程出现一级提示符
==Shell脚本==
- 定义:执行Command命令的文件叫做shell脚本,其按行解释。
- 编写:纯文本文件,可以使用任何文本编辑器编写,通常以
.sh为后缀名。 - 执行:
sh script_name - 格式:

Linux 进程
Definition of process and multi-process
进程:正在运行的程序
- 前提:程序被系统载入内存并运行
- 进程号(Process ID):每个进程的标号
ps查看当前运行的程序及其进程号
多进程
- 分时技术
- 起因:Linux不可能在一个CPU上同时处理多个任务请求
- 实现:所有的任务请求排成一个队列,系统按顺序每次从队列中抽取一个任务执行很短的时间(几毫秒)然后就又将它排到任务队列的末尾,如此不断循环执行所有任务
- 任务/作业:一个被用户指定运行的程序
- 多用户:每个进程都有运行者的标志,用户可以控制自己的进程(如:分配优先级、终止进程等
运行后台进程
前台与后台
- 前台进程:程序控制着标准输入/输出,程序运行时shell被暂时挂起。在此过程中,用户不能再执行其他程序。
- 后台进程:不必等待程序运行结束就可以执行其他程序。
- 终端里只能同时存在一个前台任务,但可有多个后台任务。
运行后台进程
- 在命令最后加上
&即为控制后台程序,如:sleep 60 &为后台任务,sleep 60为前台任务 - 前台转后台:
ctrl+z将前台任务挂起,再用bg将程序转为后台运行bg jobnumber将被挂起的进程转化到后台运行,jobnumber是通过jobs查出来的作业号
- 后台转前台:
fg - 查看后台运行或被挂起的进程:
jobs- 第一列的
1 2 3代表了作业号 +表示当前作业-表示当前作业之后的作业jobs -l显示进程号
- 第一列的
进行进程控制
- 查看正在运行的程序:
psps常用选项参数:
- 列标志的含义:
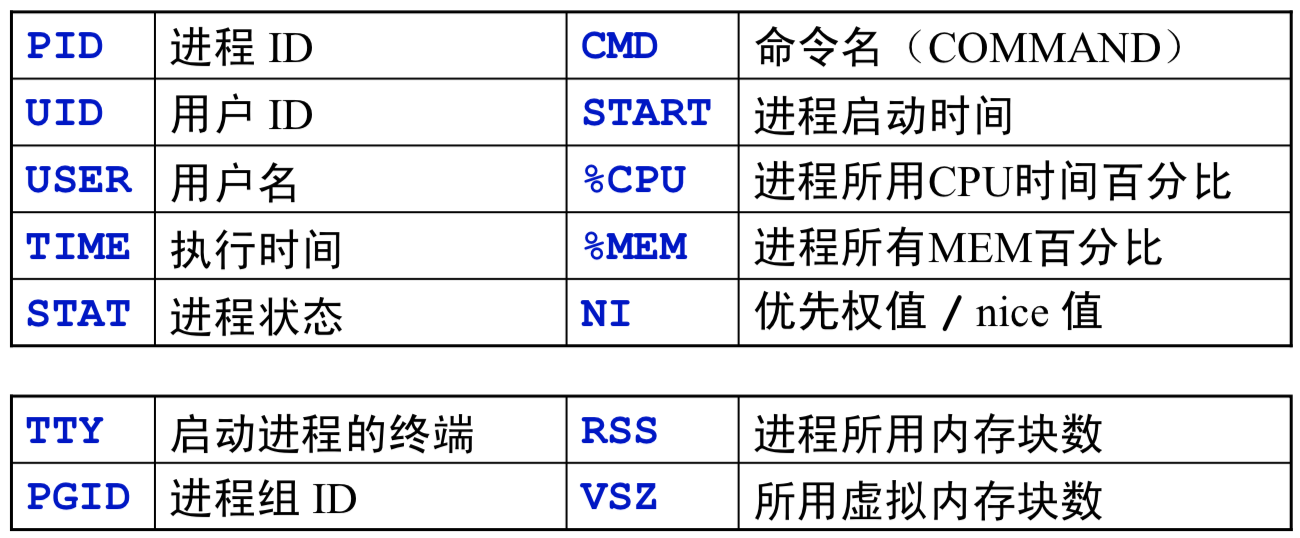
- 进程状态:

- 还可以用两种方法指定输出格式、进程排序等
- 用户退出系统仍继续运行的进程:
nohup 命令 [选项] [参数] &- 输出通常重定向到指定文件
- ==进程的优先权==
- 定义:
nice为优先权值,从-20到19,越小优先权越大,缺省值为0 - 查看进程的
nice值:ps -l 进程号,其中NI对应的即为 - 启动进程时指定优先级:
nice -n 命令 &
- 普通用户只能增加nice值,系统管理员才能降低nice值
- nice值不仅限于后台任务,前台也可
e.g. nice -5 sleep 60
- ==进程运行后调整nice值:==
renice n [-p pid] [-u user] [-g pgid]- root可以提高进程优先权,在系统资源紧张时可以为急用的进程分得更多的CPU时间
- 注意:
- 这里的
n前面没有-,但同样可正可负 - -p可以省略
- 若
[-p pid]全部省略 则代表改变指定用户的所有进程的nice值 - 普通用户一旦增加某进程nice值就无法恢复
- 这里的
- 定义:
- 终止进程
- 终止前台:
ctrl+c - 终止后台:
kill- 正常结束:
kill pid - 强制结束:
kill -9 pid - 注意:
- 使用前需要先用
ps查看进程pid kill -9在杀死进程的同时将杀死所有子进程
- 使用前需要先用
- 正常结束:
- 终止前台:
==常用相关命令==


- 更多bash内部命令:
man bash
Rexp 正则表达式
-
基本元字符集及其含义
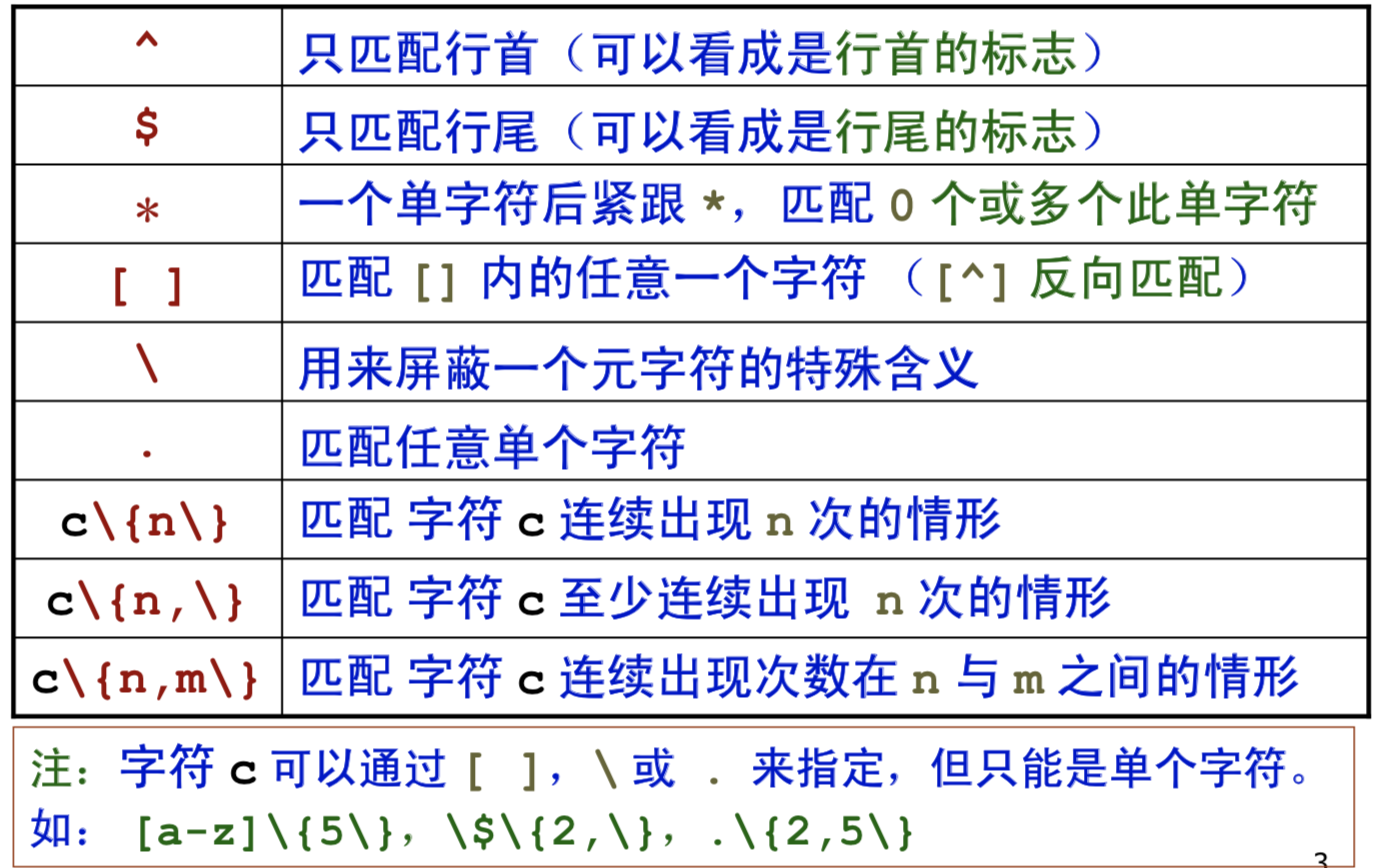
- 元字符集举例
.匹配的单字符可以为字母或者数字或者符号^和$分别匹配行首和行尾- 注意
^如果在[]中则代表着反义e.g. ^[^s]代表不以s开头的行
- 注意
*必须和前面的字符结合才有意义,必须是某个单字符后紧跟*表示匹配0个或多个此字符e.g. .*代表匹配任意多个字符^.*$代表匹配任意行
\仍然是起到的一个转义字符的作用[]匹配的是一个字符\{ \}匹配某个模式出现的次数,其中的\其实是为了转义{}
- 常用正则表达式:

Linux 文本过滤
==grep命令==
grep家族
- 作用:在一个或多个文件中查找某个字符模式所在的行并将结果输出到屏幕上
- grep家族:grep、egrep、fgrep
grep使用
grep [选项] pattern file1 file2 ...pattern可以是正则表达式(用单引号括起来) 或字符串(加上双引号) 或一个单词file1 file2 …可以作为命令的输入 输入也可以来自标准输入或管道
grep -f pattern_file file1 file2- 适用于每行写一个匹配模式的匹配文件,用
-f选项指定从文件中读入匹配模式
- 适用于每行写一个匹配模式的匹配文件,用
- 常用参数选项:

- 一些用法举例:
- 查询多个文件使用通配符:
* e.g. *.txt - 匹配空行:
grep -n '^$' file_name - 精确匹配单词:
\< \>可匹配以某个单词开头结尾的词 - 递归搜索目录中的所有文件:
-r
- 查询多个文件使用通配符:
sed流编辑器
==awk编程==
awk 介绍
- 作用:处理数据和生成报告
- 原理:逐行扫描输入,按照给定的模式查找出匹配的行,然后对这些行执行
awk命令指定的操作
awk 三种调用方式
awk [-F 字段分隔符] 'awk_script' input_fileawk -f awk_script input_file- 将
awk命令插入脚本文件,生成awk可执行脚本文件,然后在命令行中直接键入脚本文件名来执行 awk命令的一般形式:
BEGIN {actions}和END {actions}是可选的
- 重定向与管道
awk '{print $1, $2 > "output"}' datafile
awk '{"date" | getline d; print d}'
awk中的模式匹配
- 正则表达式:
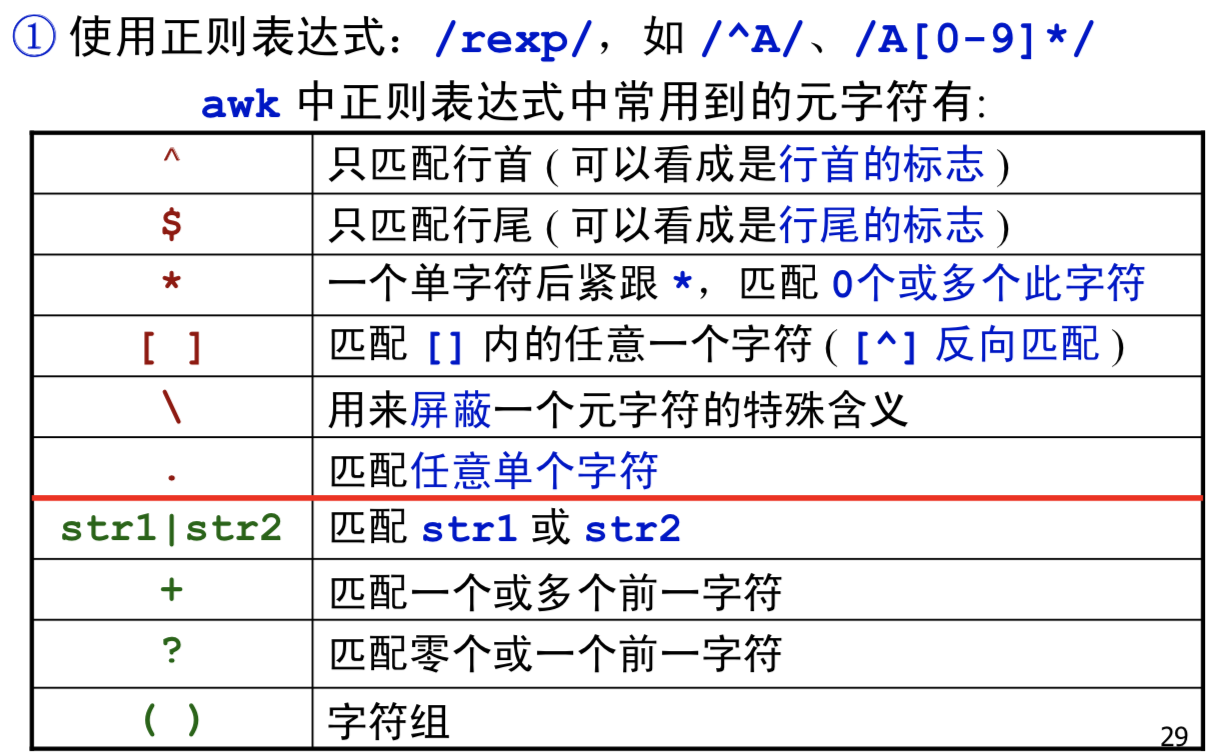
- 布尔表达式:

- 复合表达式:

==sort排序==
-
默认按照升序排序:
sort file_name -
按照降序排序:
sort -r file_name -
更多的用法可以参照参照这个博客
-
[root@www ~]# sort [-fbMnrtuk] [file or stdin] 选项与参数: -f :忽略大小写的差异,例如 A 与 a 视为编码相同; -b :忽略最前面的空格符部分; -M :以月份的名字来排序,例如 JAN, DEC 等等的排序方法; -n :使用『纯数字』进行排序(默认是以文字型态来排序的); -r :反向排序; -u :就是 uniq ,相同的数据中,仅出现一行代表; -t :分隔符,默认是用 [tab] 键来分隔; -k :以那个区间 (field) 来进行排序的意思
-
Vim 编辑器
How to use Vim?
工作模式
模式转换图: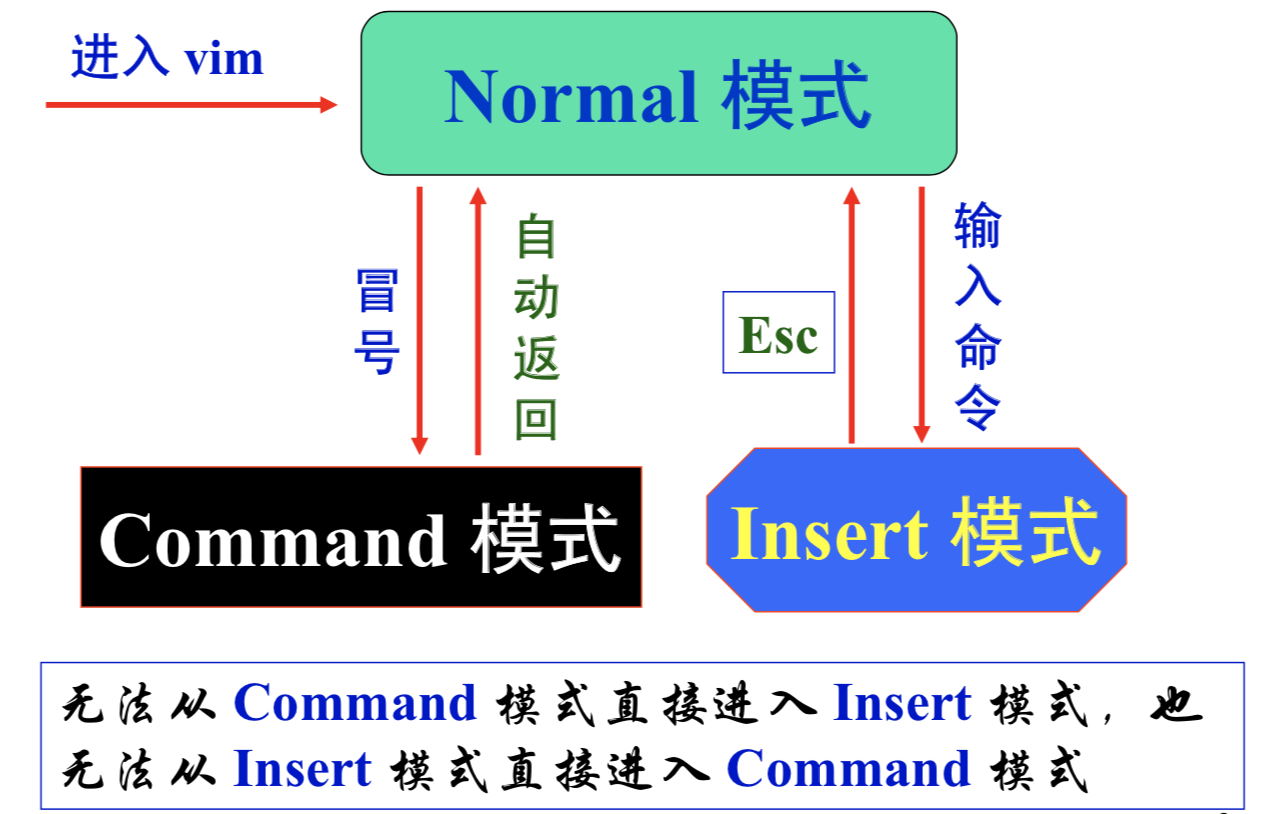
Normal(正常模式、编辑模式)
- 启动vim的默认模式,也可从其他模式用
esc进入该模式 - 该模式下输入的任何字符虽然不会在屏幕上显示,但都被当作编辑命令来解释
Insert(插入模式)
- 该模式下输入的任何字符都被vim当作文件内容保存起来并显示在屏幕上

Command(命令模式、末行模式)
- Normal转Command:冒号
:Command转Normal:esc - 该模式下vim会在窗口最后一行显示一个
:作为提示符,等待用户输入命令,输入完后按<回车>执行命令(最后一行也称为状态行,显示文件名和光标所在位置等信息
Vim的启动
vim file_name或者vi file_name,若想同时编辑:vi file1 file2- 进入vim时的附加操作:
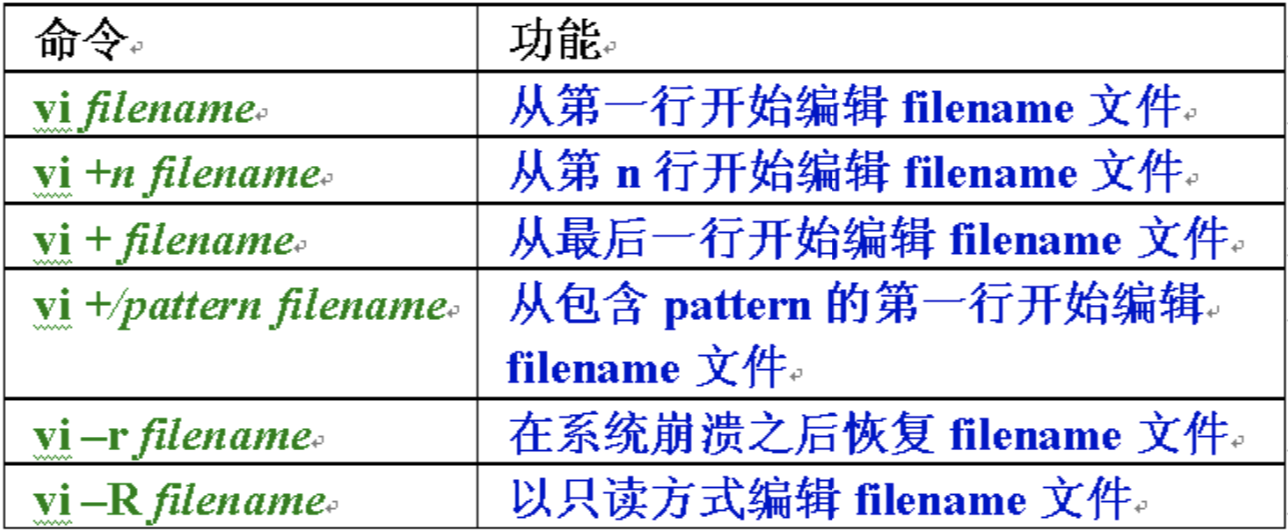
Vim的退出

Functions of Vim
How to edit?
光标移动
Intro to OS
操作系统的特征
- 并发:处理多个同时活动的能力
- 共享:操作系统与多个用户程序共同使用计算机系统中的资源
- 虚拟:一个物理实体映射为若干个对应的逻辑实体——分时或分空间(虚拟技术是操作系统管理系统资源的重要手段
- 随机:操作系统必须随时对以不可预测的次序发生的事件进行响应
处理器管理
处理器及中断
处理器

==中断==
-
定义:程序执行过程中,遇到急需处理的事件时,暂时中止CPU上现行程序的运行,转去执行相应的事件处理程序,待处理完成后再返回原程序被中断处或调度其他程序执行的过程。
-
Why:实现并发工作/处理突发事件/满足实时要求,操作系统是由“中断驱动”的
-
分类:强迫性中断/自愿性中断
- ==中断与异常==
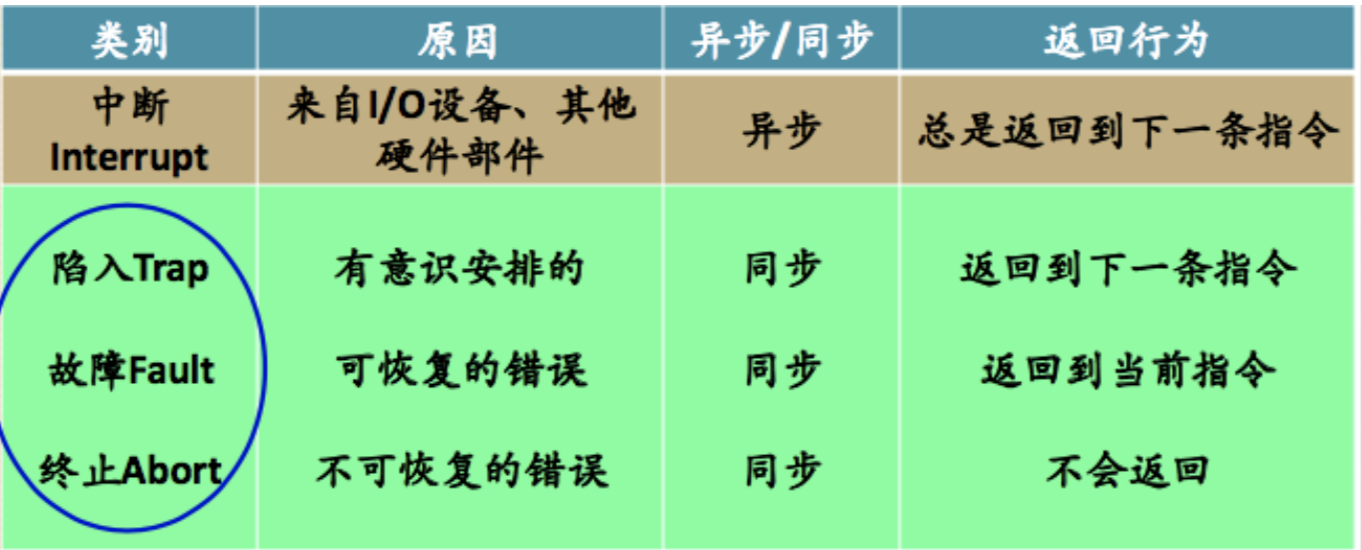
- 中断/异常响应要做的四件事:发现中断源->保护现场->转向处理中断/异常事件的处理程序->恢复现场
- 硬件——中断/异常响应
- 捕获中断源发出的中断/异常请求,以一定方式响应,将处理器控制权交给特定的处理程序
- 软件——中断/异常处理程序
- 识别中断/异常类型并完成相应的处理
中断 异常 由与现行指令无关的中断信号触发的(异步的) 由处理器正在执行现行指令而引起 指令之间才允许中断 一条指令执行期间允许响应异常 一般来说,中断处理程序提供的服务不是为当前进程所需的 异常处理程序提供的服务是为当前进程所用 中断的发生与CPU处在用户模式或内核模式无关 异常包括很多方面,有出错(fault),也有陷入(trap)等 中断是异步事件,可能随时发生,与处理器正在执行的内容无关 异常是同步事件,它是某一个特定指令执行的结果 - 中断优先级:按中断的紧迫程度分类,优先响应优先级高的中断
进程及其实现
==定义和性质==
-
是可并发执行的程序在某个数据集合上的一次计算活动,也是操作系统进行资源分配和保护的基本单位。可以使用
ps来查看进程。 -
进程的作用
- 能描述程序动态执行过程的概念
- 解决系统的“共享性”,正确描述程序的执行状态
-
区分进程与程序
-
进程 程序 动态 静态 暂时 永久 代码+数据+状态 代码+数据 多 一
-
-
操作系统给每个进程都分配了一个地址空间
- 每个程序都能看到一片完整连续的地址空间,这些空间并没有直接关联到物理内存,而是操作系统提供了内存的一种抽象概念,使得每个进程都有一个连续完整的地址空间。
- 在程序的运行过程,再完成虚拟地址到物理地址的转换。
- 进程的地址空间是分段的,存在所谓的数据段,代码段,bbs段,堆,栈等等。每个段都有特定的作用。
- 堆(heap)和栈(stack)的区别?

==进程常用命令行操作==
ps -A显示所有进程信息ps -u root显示指定用户信息ps -ef显示所有进程信息 连同命令行ps -ef|grep sshps与grep结合 查找特定进程ps aux列出目前所有的正在内存中的程序-
Ps aux|more可以用管道和more连接起来分页查看目前所有正在内存中的程序
==状态和转换==
- 运行态:进程占有处理器运行
- 就绪态:指进程具备运行条件等待处理器运行
- 等待态:指进程由于等待资源、输入输出、信号而不具备运行条件
- 状态转换:
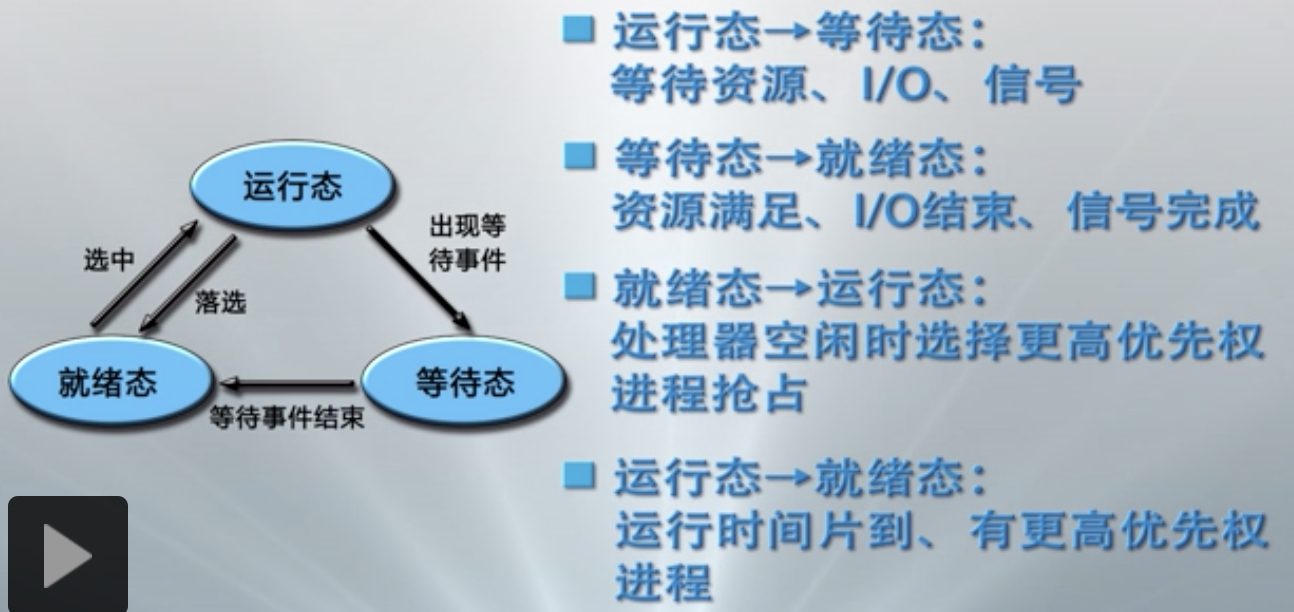
- ==进程挂起==
- 起因:运行资源不足
- 表现:性能低和死锁
- 解决方法:进程挂起(剥夺某些进程的内存及其他资源,调入OS管理的对换区,不参加进程调度,待适当时候再调入内存、恢复资源、参与运行
- 注意:挂起态与等待态有着本质区别,后者占有已申请到的资源处于等待,前者没有任何资源

- 挂起就绪态表明了进程具备运行条件但目前在辅存储器中,只有当它被对换到主存才能被调度执行。
- 挂起等待态则表明了进程正在等待某一个事件且在辅存储器中。
描述和组成
- 进程控制块PCB
- OS用于记录和刻画进程状态及环境信息的数据结构
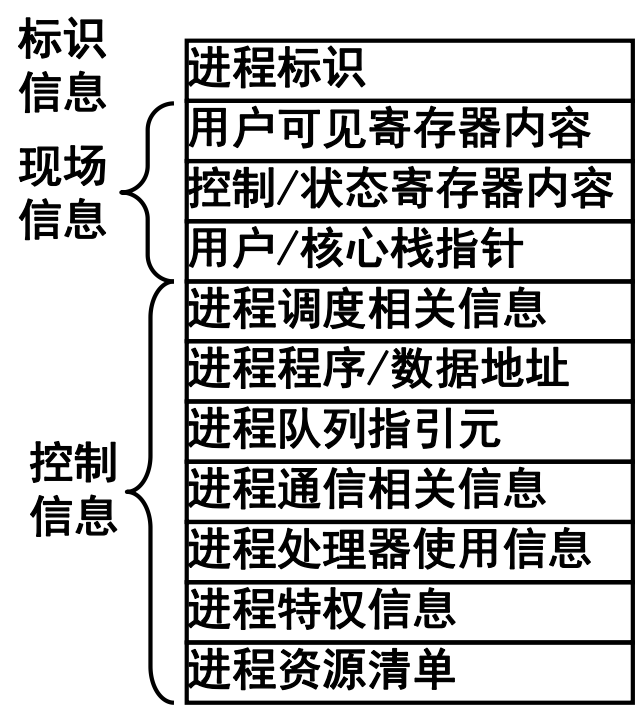
- OS用于记录和刻画进程状态及环境信息的数据结构
- 进程(内存)映像PI
- 定义:某一时刻进程的内容及其执行状态的集合:进程控制块、进程程序块、进程数据块、核心栈

- 进程上下文PC
- 定义:OS中的进程物理实体和支持进程运行的环境合成进程上下文,包括:用户级上下文、寄存器上下文、系统级上下文
切换与模式切换
- 进程切换
- 定义:从正在运行的进程中收回处理器,让待运行进程来占有处理器运行
- 实质:被中断运行过程与待运行进程的上下文切换
- 处理流程:保存被中断进程的上下文->转向进程调度->恢复待运行进程的上下文
- 模式切换(又称:处理器切换
- 分类
- 用户模式到内核模式
- 由中断/异常/系统调用中断用户进程执行而触发
- 内核模式到用户模式
- OS执行中断返回指令将控制权交还用户进程而触发
- 用户模式到内核模式
- 分类
控制和管理
- 进程实现的队列模型:
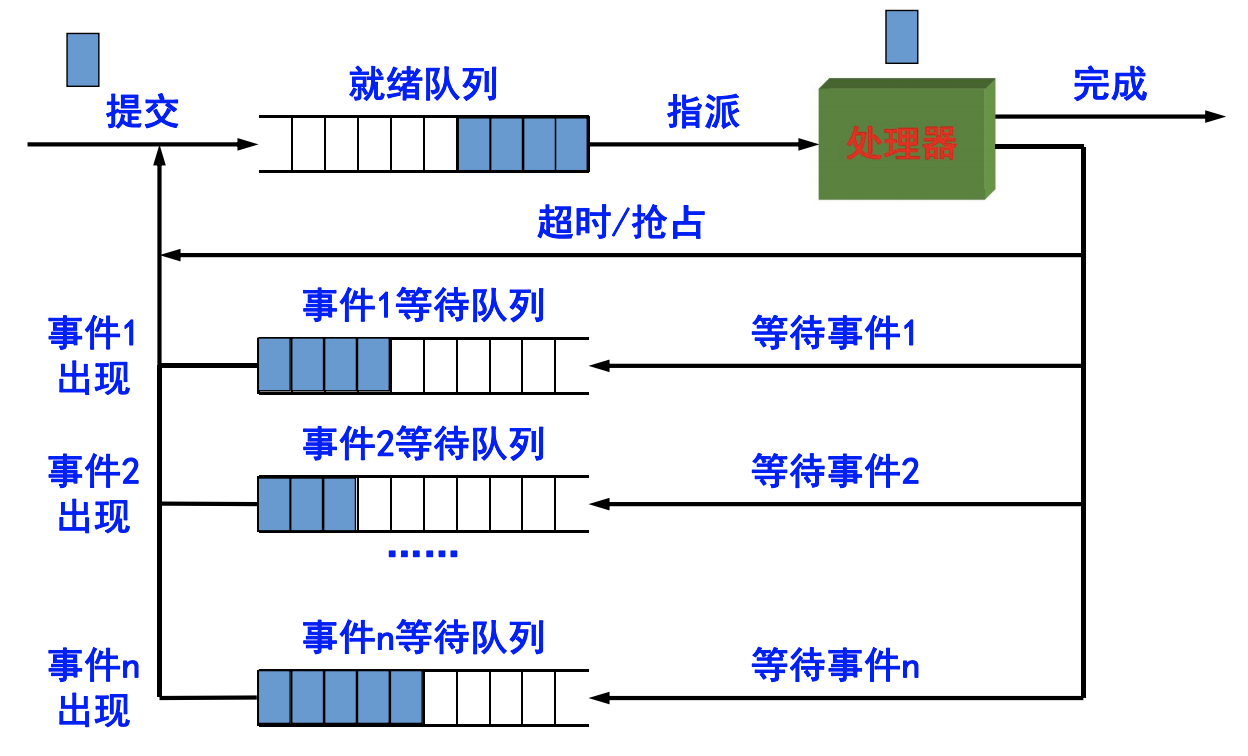
- 队列管理:进程管理的核心模块
- OS建立多个进程队列,包括就绪队列和等待队列
- 按需组织为FIFO和Priority Queue
- 进程与资源调度围绕进程队列展开
- 进程创建:进程表加一项,申请PCB并初始化,生成标识,建立映像,分配资源,移入就绪队列
- 进程撤销:从队列中移除,归还资源,撤销标识,回收PCB,移除进程表项
- 进程阻塞:保存现场信息,修改PCB,移入等待队列,调度其他进程执行
- 进程唤醒:等待队列中移出,修改PCB,移入就绪队列(该进程优先级高于运行进程触发抢占)
- 进程挂起:修改状态并出入相关队列,收回内存等资源送至对换区
- 进程激活:分配内存,修改状态并出入相关队列
- 其他:如修改进程特权
线程及其实现
单线程
- 传统进程是单线程结构进程:
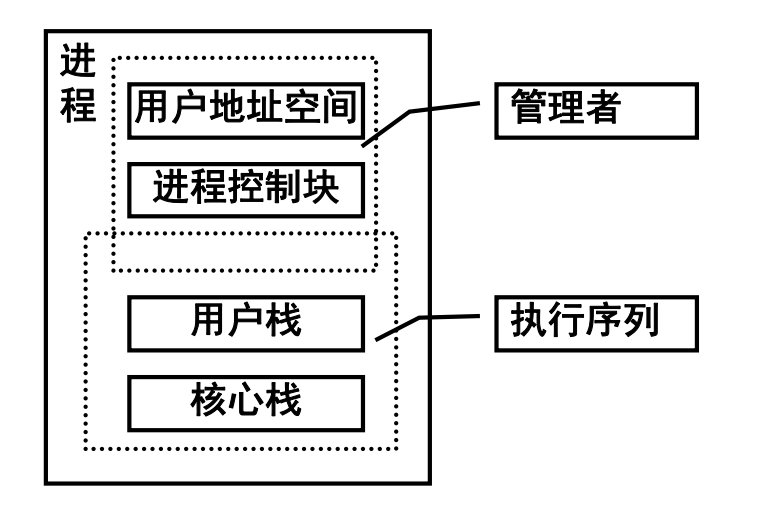
- 在并发程序设计上的问题
- 进程切换开销大
- 进程通信开销大
- 限制了进程并发的粒度
- 降低了并行计算的效率
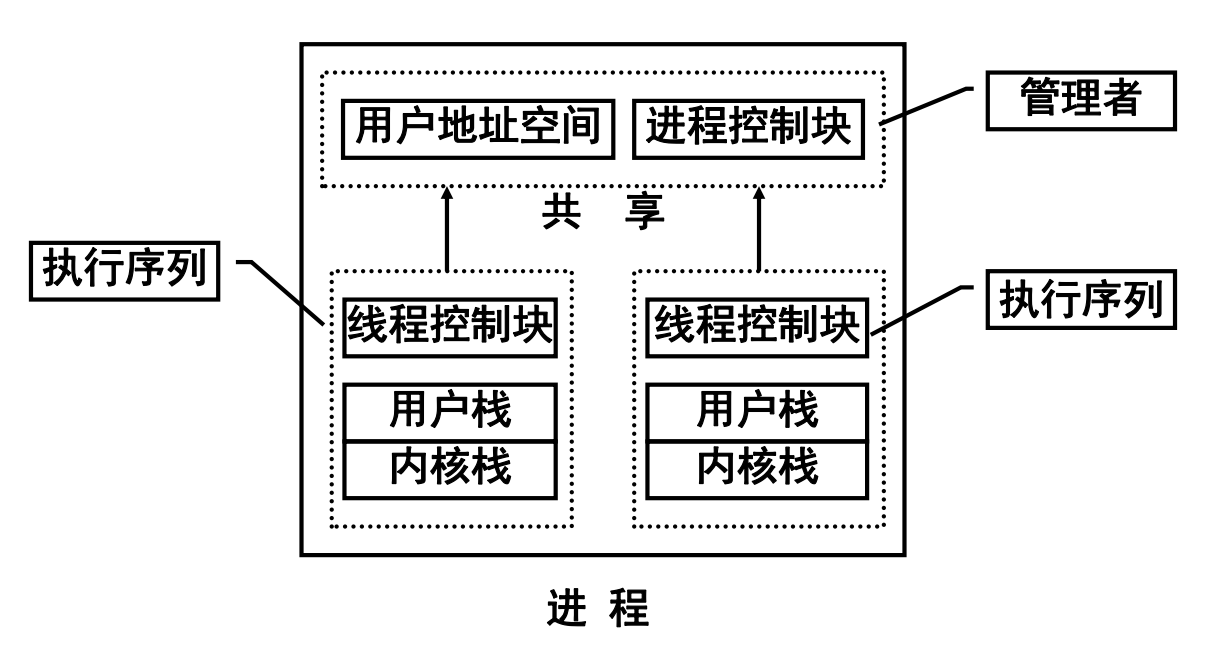
多线程
- 在多线程环境中,进程是操作系统中进行保护和资源分配的独立单位:
==进程和线程==
-
引入进程的动机
- 使多个程序可以并发执行,以改善资源使用率和提高系统效率
-
引入线程的动机
- 减少进程并发执行时所付出的时空开销,使得并发粒度更细、并发性更好
-
解决思路
- 分离进程的两项功能:“独立分配资源”与“被调度分派执行”
- 进程:资源分配单位,无需频繁切换
- 线程:调度单位,体量小,频繁切换
-
线程是进程的一条执行路径,是调度的基本单位,同一个进程中的所有线程共享进程获得的贮存空间和资源
-
进程只有挂起状态,线程有运行、就绪和睡眠三种状态

处理器调度
==Linux和Windows处理器调度算法==
- 常用调度算法:先来先服务/最短作业优先/最短剩余时间优先/最高响应比优先/时间片轮转
- 最高响应比优先算法
- 公式为$R=(w+s)/s$,其中w为等待时间,s为计算时间
- 特点:兼顾作业的等待时间和计算时间
- 最高响应比优先算法
- 处理调度的层次
- 高级调度
- 多道批处理系统,选择作业进入主存
- 分时系统通常不需要
- 中级调度
- 外存与内存中的进程对换
- 提高主存的利用率
- 低级调度
- 就绪->运行
- 操作系统必备
- 高级调度
- 处理器的三级调度模型:

- 进程调度与作业调度:

==选择调度算法的原则==
- 资源(CPU)利用率
- CPU利用率=CPU有效工作时间/CPU总的运行时间
- CPU总的运行时间=CPU有效工作时间+CPU空闲等待时间
- 吞吐率
- 定义:单位时间内CPU处理作业的数目
- 增加吞吐量可以从两个方面入手:
- 减少开销(操作系统开销,上下文切换)
- 系统资源的高效利用(CPU,I/O设备)
- 公平性
- 避免饥饿
- 响应时间
- 交互式进程从提交一个请求(命令)到接收到响应之间的时间间隔称响应时间
- 实时系统、分时系统的重要指标
- 周转时间
- 批处理用户从作业提交给系统开始,到作业完成为止的时间间隔称作业周转时间
- 批处理系统的重要指标
==平均作业周转时间==
- 作业周转时间
- 如果作业i提交给系统的时刻是$t_s$,完成时刻是$t_f$,则该作业的周转时间为:$t=t_f-t_s$
- 周转时间包括等待时间和运行时间
- 平均作业周转时间:$T=\frac{\sum t_i}{n}$
- 通常用该指标来衡量对同一作业流施行不同作业调度算法时,它们呈现的调度性能。数值越小越好。
- 如果作业i的周转时间为$t_i$,所需运行时间为$t_k$,则成$w_i=t_i/t_k$为该作业的带权周转时间
- 平均作业带权周转时间:$W=\frac{\sum w_i}{n}$
- 通常用该指标来衡量对不同作业流施行同一作业调度算法时,它们呈现的调度性能。数值越小越好。
==Spark集群对应用的调度策略==
- 应用间调度
- 策略1. 资源静态分区:OS(2).p19
- 资源静态分区是指整个集群的资源被预先划分为多个partitions,资源分配时的最小粒度是一个静态的partition。
- 根据应用对资源的申请需求为其分配静态的partition(s)是Spark支持的最简单的调度策略。
- 若Spark集群配置了static partitioning的调度策略,则它对提交的多个应用间默认采用FIFO顺序进行调度。
- 每个获得执行机会的应用在运行期间可占用整个集群的资源,这样做明显不友好,所以应用提交者通常需要通过设置
spark.cores.max来控制其占用的core/memory资源。
- 策略2. 动态共享CPU cores:OS(2).p20
- 若Spark集群采用Mesos模式,可以采用该策略;
- 每个应用仍拥有各自独立的cores/memory,但当应用申请资源后并未使用时(即分配给应用的资源当前闲置),其它应用的计算任务可能会被调度器分配到这些闲置资源上。
- 当提交给集群的应用有很多是非活跃应用时(即它们并非时刻占用集群资源),这种调度策略能很大程度上提升集群资源利用效率。
- 风险是:若某个应用从非活跃状态转变为活跃状态时,且它提交时申请的资源当前恰好被调度给其它应用,则它无法立即获得执行的机会。
- 策略3. 动态资源申请:OS(2).p21
- 它允许根据应用的workload动态调整其所需的集群资源。
- 若应用暂时不需要它之前申请的资源,则它可以先归还给集群。
- 当它需要时,可以重新向集群申请。当Spark集群被多个应用共享时,这种按需分配的策略显然是非常有优势的。
- 策略1. 资源静态分区:OS(2).p19
- 应用内调度
- 默认采用FIFO的调度策略:OS(2).p22
- 每个job被分解为不同的stages;
- 当多个job各自的stage所在的线程同时申请资源时,第1个job的stage优先获得资源;
- 如果job queue头部的job恰好是需要最长执行时间的job时,后面所有的job均得不到执行的机会,这样会导致某些job(s)饿死的情况。
- 也可以被配置为“fair sharing”:OS(2).p23
- Spark对不同jobs的stages提交的tasks采用Round Robin的调度方式,如此,所有的jobs均得到公平执行的机会。因此,即使某些short-time jobs本身的提交时间在long jobs之后,它也能获得被执行的机会,从而达到可预期的响应时间。
- 要启用fair sharing调度策略,需要在spark配置文件中将spark.scheduler.mode设置为FAIR。
- 注意:fair sharing调度也支持把不同的jobs聚合到一个pool,不同的pools赋予不同的执行优先级。
- 这是FIFO和fair sharing两种策略的折衷策略,既能保证jobs之间的优先级,也能保证同一优先级的jobs均能得到公平执行的机会
- 默认采用FIFO的调度策略:OS(2).p22
并发程序设计
==并发进程==
A. 串行vs并发
- 并发:同一个时间段内多个进程/线程同时运行
- 并发大大提高系统效率

B. 并发带来的问题
- 数据一致性问题
- 丢失修改
- 不可重复读
- 指在一个事务/进程内,多次读同一数据。
- 即:在这个事务还没有结束时,另外一个事务/进程也访问该同一数据。那么,在第一个事务/进程中的两次读数据之间,由于第二个事务/进程的修改,那么第一个事务/进程两次读到的的数据可能是不一样的。这样在一个事务/进程内两次读到的数据是不一样的,因此称为是不可重复读。
- 读脏数据
- 指当一个事务/进程正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库/进程中,这时,另外一个事务/进程也访问这个数据,然后使用了这个数据。
- 幻读
- 当事务不是独立执行时发生的一种现象
- 例如第一个事务对一个表中的数据进行了修改,比如这种修改涉及到表中的“全部数据行”。同时,第二个事务也修改这个表中的数据,这种修改是向表中插入“一行新数据”。
- 以后就会发生操作第一个事务的用户发现表中还存在没有修改的数据行,就好象发生了幻觉一样。
- 资源竞争问题
- 死锁
- 一组进程都获得部分资源,又要申请彼此占有的资源->死锁(太贪心了!
- 死锁条件
- 互斥条件、不可剥夺、请求和保持、循环等待
- 饥饿
- 进程一直抢占不到资源
- 解决:SJF调度方法 ( 最短作业优先算法)
- 死锁
C. 并发程序的关系
- 完全无关
- 并发进程执行与时间无关,不会产生任何错误
- 条件:$R(P_1)\cap W(P_2) \cup R(P_2)\cap W(P_1)\cup W(P_1)\cap W(P_2) = \phi$
- 其中$R(P_i)$表示程序$P_i$在执行期间引用的变量集,$W(P_i)$表示程序$P_i$在执行期间改变的变量集
- 竞争
- 彼此不知道对方的存在
- 竞争独占性资源
- 条件:需要互斥
- 进程互斥指若干个进程要使用同一共享资源时,任何时刻最多允许一个进程去使用,其他要使用该资源的进程必须等待,直到占有资源的进程释放该资源。
- 问题:死锁、饥饿
- 共享合作
- 进程不知道彼此的存在
- 有共享数据:变量、文件、数据库等
- 互斥需求
- 问题:数据一致性问题、死锁、饥饿等
- 通信合作
- 进程知道彼此的存在
- 通过通信协作
- 同步需求
- 死锁、饥饿
D. 进程同步
- 多个进程中发生的事件存在某种时序关系,需要相互合作,共同完成一项任务。
- 具体的说,一个进程运行到某一个点时,要求另一伙伴进程为它提供消息,在未获得消息之前,该进程进入阻塞态,获得消息后被唤醒进入就绪态。
- 进程互斥关系是一种特殊的进程同步关系,即逐次使用互斥共享资源, 也是对进程使用资源次序上的一种协调。
==信号量与PV操作==
- 信号量
- 一种特殊变量
- 交互进程在关键点上一直等待直到接收到特殊变量值
- P操作原语和V操作原语
- 对信号量进行特殊操作
- P:检测,V:增量
- 对信号量可以实施的操作:初始化、P和V(P、V分别 是荷兰语的test(proberen)和increment(verhogen))

- 用PV操作解决进程间互斥问题

==管程==
- 定义:由局部与自己的若干公共变量和所有访问这些公共变量的过程(临界区)所组成的软件模块
- 特性
- 共享性
- 对外接口可以被多个进程共享
- 安全性
- 管程的局部变量只能由管程自己访问,管程也不访问任何外部变量
- 互斥性
- 一次只让一个进程(线程)进入管程
- 共享性
- 进程vs管程
- 进程只能通过调用管程中的过程来间接地访问管程中的数据结构
- 管程提供了一种互斥机制,进程可以互斥地调用这些过程。
==管道==
- 管道(pipeline)是连接读写进程的一个特殊文件,允许进程按先进先出方式传送数据,也能使进程同步执行操作
- 发送进程以字符流形式把大量数据送入管道,接收进程从管道中接收数据,所以叫管道通信
- 管道的实质是一个共享文件,基本上可借助于文件系统的机制实现,包括(管道)文件的创建、打开、关闭和读写。
- 管道(pipe)的实现只需基于内存即可,不用在磁盘文件系统上创建一个文件。
==死锁==
-
如果在一个进程集合中的每个进程都在等待只能由该集合中的其他一个进程才能引发的事件,则称一组进程或系统此时发生死锁(等待状态将永远不能结束)
-
形成死锁的四个条件
- 互斥条件:进程互斥使用资源
- 请求与保持条件:申请新资源时不释放已占有资源
- 不可剥夺条件:一个进程不能抢夺其他进程占有的资源
- 循环等待条件:存在一组进程循环等待资源
- 注意:
- 前三个为必要条件、非充分条件
- 前三个+第四个->死锁
-
死锁解决方法
-
解除死锁
- 通常的做法有三种:一是撤销处于死锁状态的进程并收回它们的资源;二是资源剥夺法;三是进程回退。
-
死锁防止(Deadlock Prevention)
- 破坏产生死锁的四个必要条件之一或其中几个的方法,防止死锁发生
- 强制规则 -> 降低进程的并发度
- eg:资源有序分配法(采用资源有序分配法是破坏了“环路”条件,即破坏了循环等待)
-
死锁避免(Deadlock Avoidance)
-
允许前三个条件,避免第四个条件
-
并发度高
-
死锁预防是通过破坏死锁的四个必要条件来预防死锁,但这样会导致低效的资源使用和低效的进程执行;死锁避免则相反,它允许死锁的互斥、占有且等待、不可抢占三个条件,但通过明智的选择,确保永远不会到达死锁点,因此死锁避免比死锁预防允许更多的并发,所以其资源利用率要高于死锁预防。
-
-
eg:银行家算法
-
-
死锁检测和恢复(Deadlock detection & recorvery)
- 死锁定理是操作系统中用于检测死锁的充分必要条件的方法
- 死锁检测方法是对资源分配不加限制,即允许死锁发生。但是系统定时地运行一个死锁检测程序,判断系统是否已发生死锁,若检测到死锁发生,则设法加以解除。
- 死锁检测是检查资源分配图,如果资源分配图中不存在环路,则系统不存在死锁;反之如果资源分配图中存在环路,则系统可能存在死锁,也可能不存在死锁。
-
Spark
Introduction
- Overview:
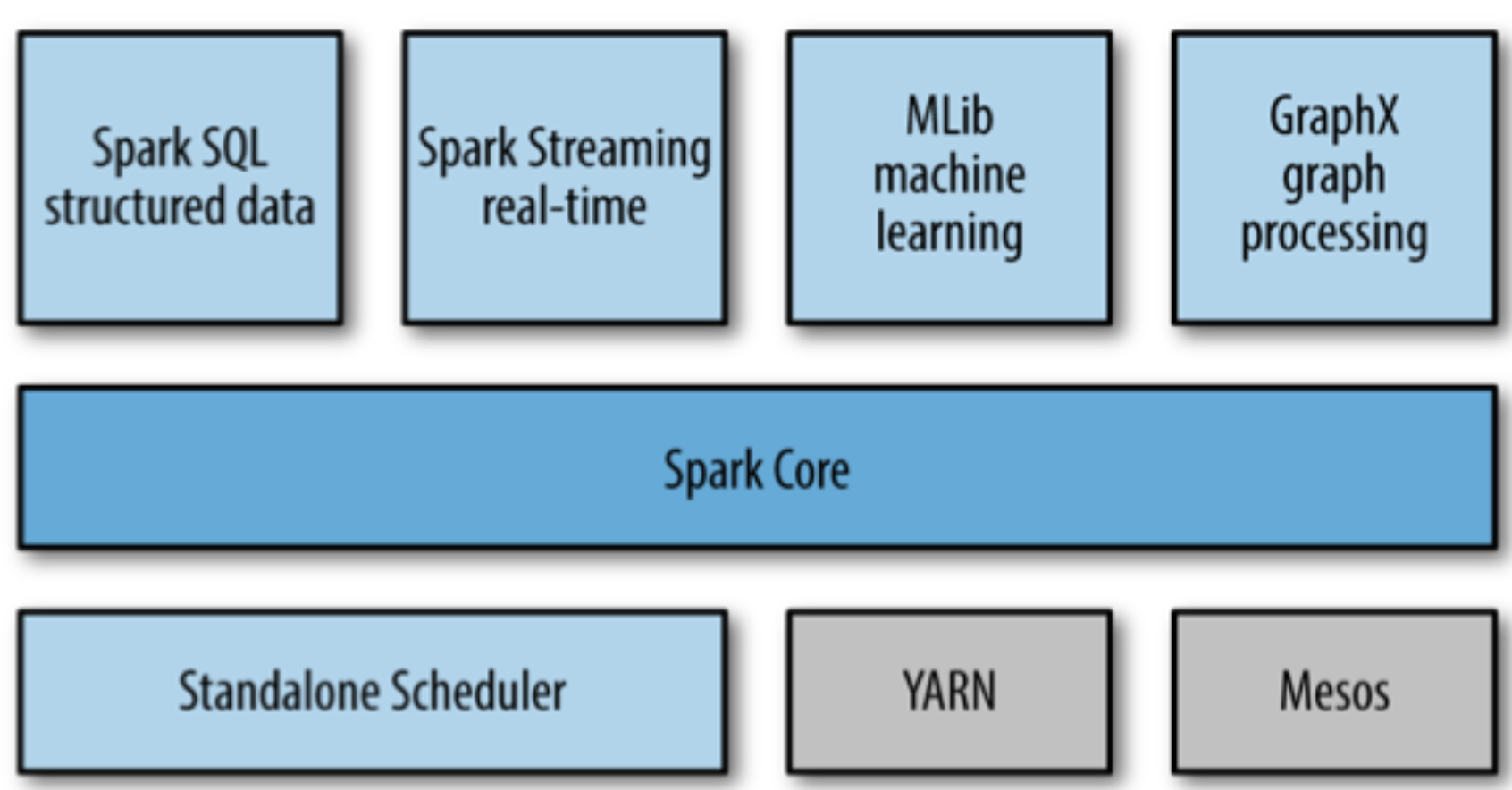
- Basic functionality of Spark, including components for:
- Task Scheduling
- Memory Management
- Fault Recovery
- Interacting with Storage Systems
- and more
- Home to the API that defines resilient distributed datasets (RDDs) - Spark’s main programming abstraction.
- RDD represents a collection of items distributed across many compute nodes that can be manipulated in parallel.
How to install it?
安装及配置使用环境
- Pip install pyspark and take a look at its document here
- Then type
pyspark, here you go - 简略Spark的输出:

使用
- You can view Spark jobs at
http://localhost:4040 - 运行脚本需要用spark-submit:
$SPARK_HOME/bin/spark-submit my_script - 停止运行SparkContext使用:
sc.stop(),必须停掉当前的才能开启下一个
Resilient Distributed Dataset (RDD) Basics
- 定义
- 不变的、容错的、并行的数据结构
- 显式地将数据存储到磁盘和内存,控制数据的分区
- 作用
- 支持四种模型:迭代算法、关联查询、MapReduce、流式处理
- 构建RDD:
- RDD Transformations和Actions的核心API:

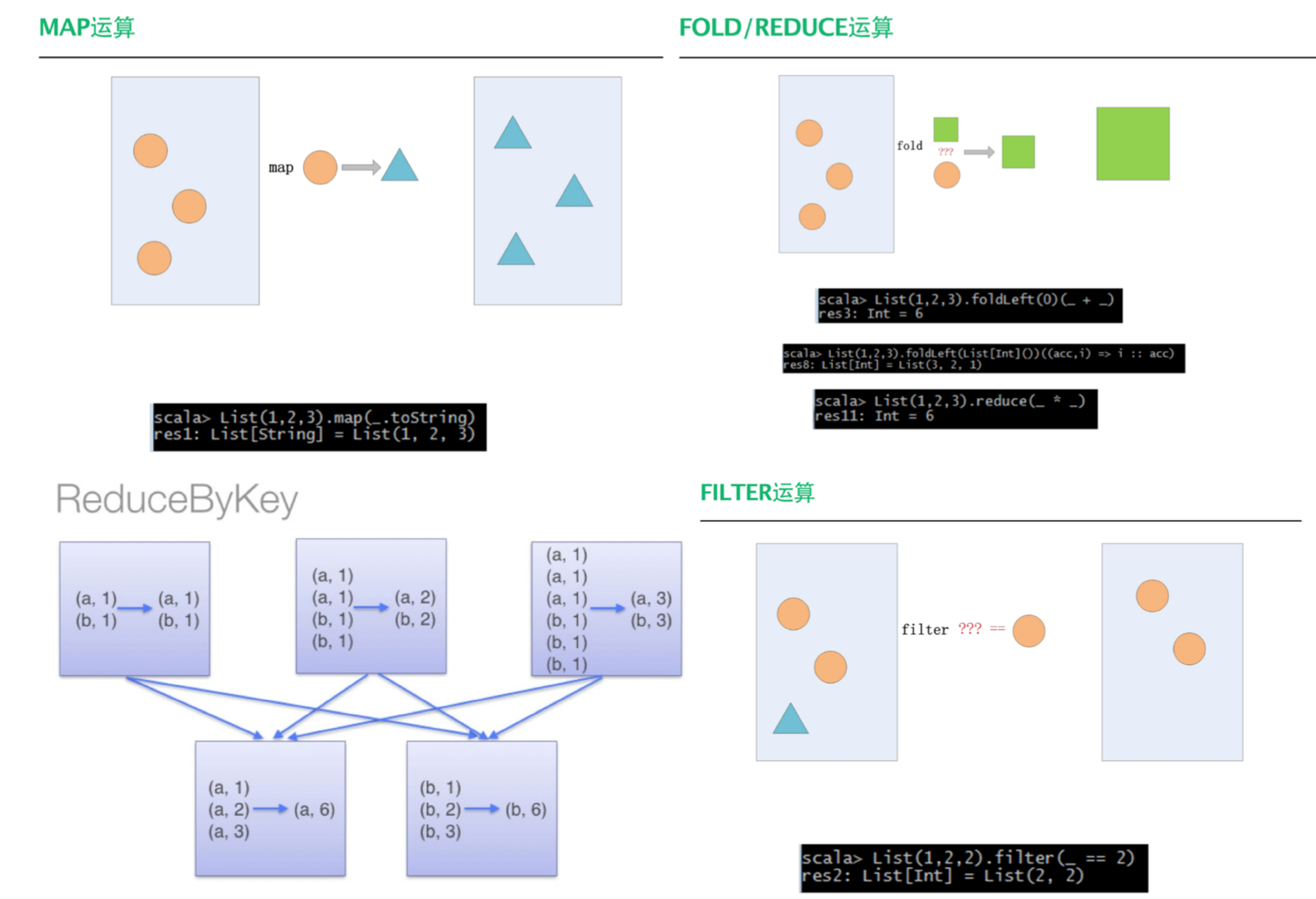


Using Spark
- Persistance in Spark
- By default, RDDs are computed each time you run an action on them.
- If you like to reuse an RDD in multiple actions, you can ask Spark to persist it using
RDD.persist(). RDD.persist()will then store the RDD contents in memory and reuse them in future actions.- Persisting RDDs on disk instead of memory is also possible.
- The behavior of not persisting by default seems to be unusual, but it makes sense for big data.
- Parallelizing in Spark:
RDD.parallelize() - Spark file loading:

-
Numeric RDD Operations:
count(); mean(); sum(); max(); min(); variance(); - Machine Learning Library in Spark — MLlib
- Example: Spam Detection, TF-IDF, Linear Regression, Classifiers, SGD, Clustering
- Spark SQL
from pyspark.sql import HiveContext
- Spark Streaming
- Structure:
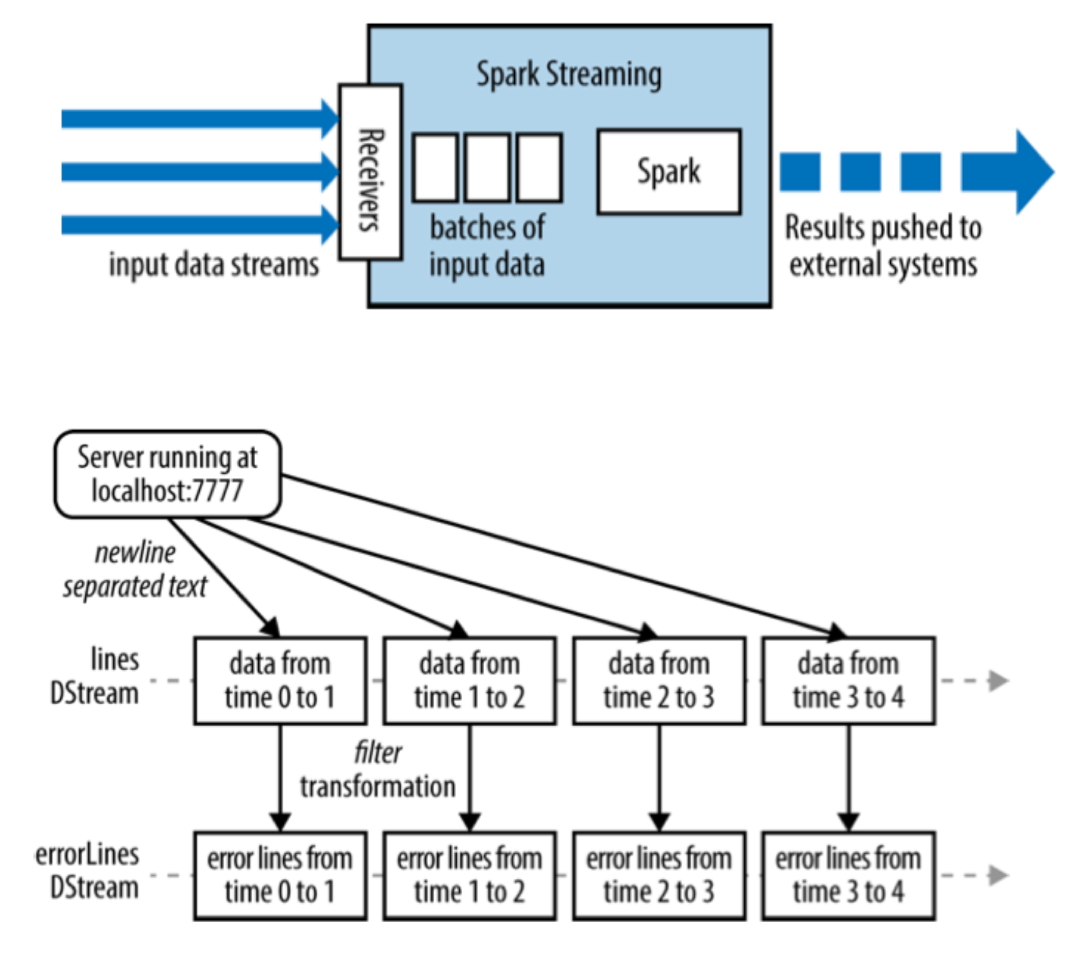
- Structure:
Hadoop vs Spark
| Hadoop | Spark | |
|---|---|---|
| 应用场景 | 单次海量数据的离线分析处理 大规模Web信息搜索 数据密集型并行计算 |
多次操作特定数据集,进行**迭代运算 ** 搜索引擎 计算相似 |
| 性能 | 适合不能全部读入内存的时候;单次读取、类似ETL(抽取、转化、加载)操作的任务,比如数据转化、数据整合等 | 适合数据不太大,内存放得下,需要重复读取同样的数据做迭代计算的时候 |
| 上手 | Java,需要学习语法 | Scala,Python和Java,支持交互式命令模式 |
| 兼容 | —— | 兼容Hadoop数据源 |
| 容错 | 硬盘静态数据,硬盘驱动失败处自动重启执行 | 内存失效,需要手动设置checkpoint |
| 数据处理 | 批处理 | 实时/批数据处理,迭代任务 |
GPU
-
Difference between CPU & GPU
CPU GPU CPUs consist of a few cores optimized for serial processing GPUs consist of hundreds or thousands of smaller, efficient cores designed for parallel performance 更多资源用于缓存 更多资源用于数据计算 带宽低 (10GB/s) 带宽非常高 (80GB/s ~ 250GB/s) -
Architecture:
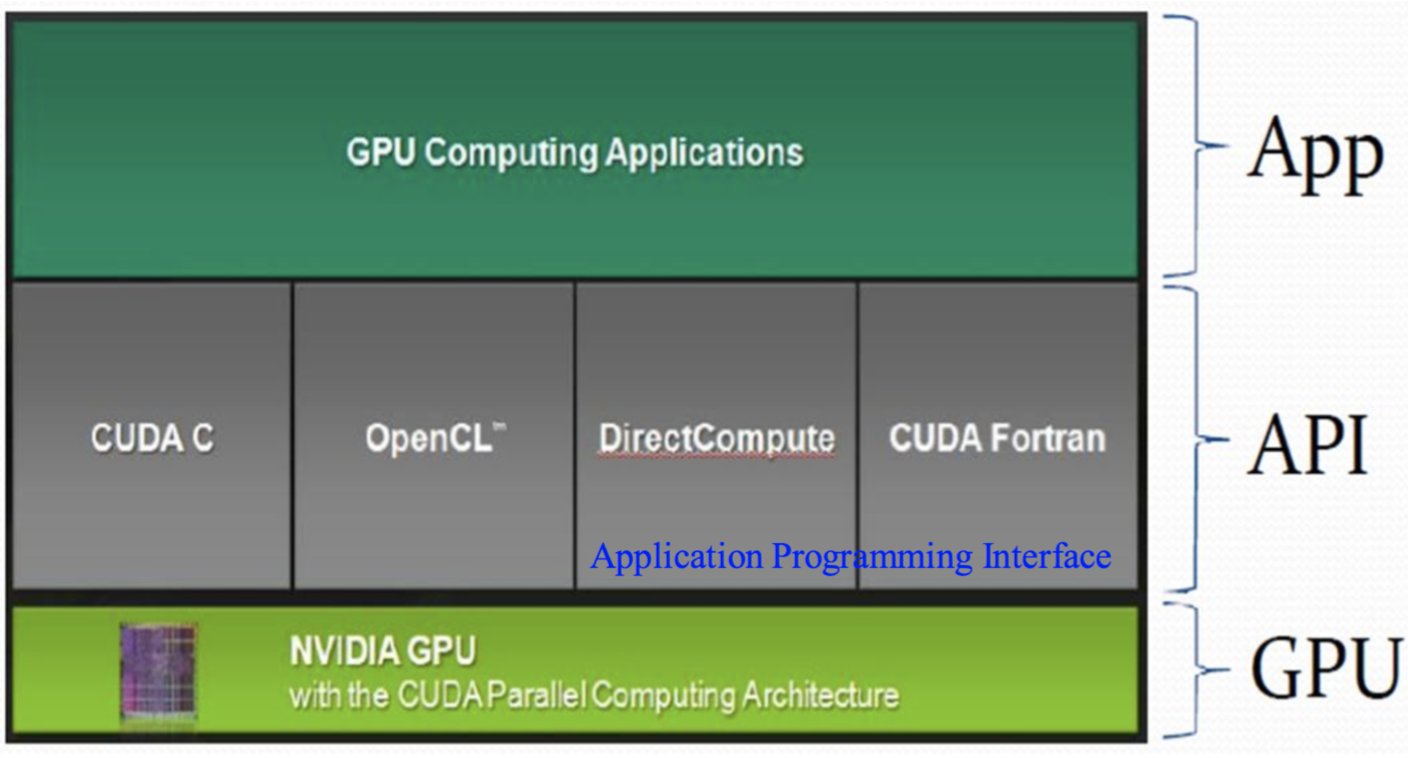
-
适用:最适合利用 CUDA 处理的问题,是可以大量并行化的问题
-
Block and Thread
- 显示芯片执行时的最小单位是thread
- 数个thread可以组成一个block
- 一个block中的thread能存取同一块共享的内存,而且可以快速进行同步的动作。
- 不同block中的thread无法存取同一个共享的内存,无法直接互通或进行同步;
- 每一个block所能包含的thread数目是有限的
-
执行相同程序的block,可以组成grid
- 每个thread都有自己的一份register和local memory空间。
- 同一个block中的每个thread则有共享的一份share memory。
- 所有的thread(包括不同block的thread)都共享一份 global memory、constant memory和 texture memory。
-
Memory部分会考自己的理解!看一下Summary的部分~
- Registers:寄存器是GPU最快的memory,kernel中没有什么特殊声明的自动变量都是放在寄存器中的。当数组的索引是constant类型且在编译期能被确定的话,就 是内置类型,数组也是放在寄存器中。
- Shared Memory: 用__shared__修饰符修饰的变量存放在shared memory。因为 shared memory是on-chip的,他相比localMemory和global memory来说,拥有高得多的bandwidth和低很多的latency。他的使用和CPU的L1cache非常类似,但是他是programmable的。 shared memory是以block为单位分配的。
- Local Memory: 如果register不够用了,那么就会使用local memory来代替这部分寄存器空间。除此外,下面几种情况,编译器可能会把变量放置在local memory: 编译期无法决定确切值的本地数组。local memory这个名字是有歧义的:在local memory中的变量本质上跟global memory在同一块存储区。所以,local memory有很高的latency和较低的bandwidth。
- Global Memory: global Memory是空间最大,latency最高,GPU最基础的memory。“global”指明了其生命周期。任意SM都可以在整个程序的生命期中获取其状态。global中的变量既可以是静态也可以是动态声明。可以使用__device__ 修饰符来限定其属性。