- Survey
- Node2Vec
- GCN
- Knowledge graph reasoning/completion
- Reinforcement Learning Query Answering
- Bioinformation
- Useful Read
I will be a research assistant under the guidance of Prof.Xiang Ren at USC next term, hence I’m reading some related papers and taking some notes for preparation.
I’ll mainly work on a relation extraction task that incorporates both text and knowledge graph. The core of the project is to generate meaningful “paths/rules” between entities on the knowledge graph to “explain” the model prediction. This is particularly important when we work on biomedical domain or product domain, etc.
I’ve read some papers on relation extraction already (you can read my blogs here), so I’m reading some context on graph embedding and knowledge graph completion this time.
Survey
All methods: Graph Embedding Techniques, Applications, and Performance: A Survey
Introduction
- Graphs (a.k.a. networks) have been used to denote information in various areas
- biology (Protein-Protein interaction networks)
- social sciences (friendship networks)
- linguistics (word co-occurrence networks)
- Graph analytic tasks
- node classification
- Definition: determining the label of nodes (a.k.a. vertices) based on other labeled nodes and the topology of the network
- Approaches
- methods which use random walks to propagate the labels
- methods which extract features from nodes and apply classifiers on them
- link prediction
- Definition: predicting missing links or links that are likely to occur in the future
- Approaches
- similarity based methods
- maximum likelihood models
- probabilistic models
- clustering
- Definition: find subsets of similar nodes and group them together
- Approaches
- attribute based models
- methods which directly maximize (resp., minimize) the inter-cluster(resp., intra-cluster) distances
- visualization
- Definition: helps in providing insights into the structure of the network
- node classification
- Challenges
- Choice of property
- Which property of the graph the embedding should preserve
- Scalability
- embedding methods should be scalable and able to process large graphs
- Dimensionality of the embedding
- Finding the optimal dimensions of the representation
- Choice of property
- Contribution of this paper
- Propose a taxonomy of approaches to graph embedding, and explain their differences
- provide a detailed and systematic analysis of various graph embedding models and discuss their performance on the various tasks
Definitions and Preliminaries
- Graph
- Graph $G(V,E)$, vertices (a.k.a. nodes) $V$, edges $E$, adjacency matrix $S$
- First-Order proximity
- Edge weights $s_{ij}$ are first-order proximities between nodes $v_i$ and $v_j$
- Second-order proximity
- Describe the proximity of the pair’s neighborhood structure
- Higher-order proximities: e.g. Katz Index, Rooted PageRank, Common Neighbors, Adamic Adar, etc.
- Graph embedding
- A mapping $f: v_i \rightarrow y_i \in \mathbb{R}^d $
- An embedding therefore maps each node to a low-dimensional feature vector and tries to preserve the connection strengths between vertices
Algorithmic approaches: A taxonomy
Graph Embedding Research Context and Evolution
-
In the early 2000s, researchers developed graph embedding algorithms as part of dimensionality reduction techniques
-
They would construct a similarity graph for a set of n D-dimensional points based on neighborhood and then embed the nodes of the graph in a d-dimensional vector space, where d ? D. The idea for embedding was to keep connected nodes closer to each other in the vector space
- Problem: scalability, time complexity is $O(\mid V \mid ^2)$
-
-
Since 2010, researcher shifted to obtaining scalable graph embedding techniques which leverage the sparsity of real-world networks
A Taxonomy of Graph Embedding Methods
Factorization based Methods
- Definition: Factorization based algorithms represent the connections between nodes in the form of a matrix and factorize this matrix to obtain the embedding.
- Matrix: node adjacency matrix, Laplacian matrix, node transition probability matrix…
- Laplacian matrix $L=D-A$
- D is a diagonal matrix which contains information about the degree of each vertex.
- A is the adjacency matrix
- L is symmetric and positive semidefinite
- Laplacian matrix $L=D-A$
- Approaches to factorize: vary based on the matrix properties.
- e.g. positive semidefinite matrix -> eigenvalue decomposition/ unstructured matrices -> gradient descent methods
- More approaches in detailed explanation: Locally Linear Embedding (LLE), Laplacian Eigenmaps, Cauchy Graph Embedding, Structure Preserving Embedding (SPE), Graph Factorization (GF), GraRep, HOPE, Additional Variants (PCA, LDA, ISOMAP, MDS for dimensionality reduction)
- Matrix: node adjacency matrix, Laplacian matrix, node transition probability matrix…
Random Walk based Methods
- Advantage: It’s especially useful when one can either one partially observe the graph or the graph is too large to measure in its entirety.
- DeepWalk
- node2vec
- Others: Hierarchical Representation Learning for Networks (HARP), Walklets, Additional Variants
Deep Learning based Methods
-
Introduction: Deep autoencoders have been used for dimensionality reduction[58] due to their ability to model non-linear structure in the data.
-
Approaches
- Structural Deep Network Embedding (SDNE)
-
Deep Neural Networks for Learning Graph Representations (DNGR)
- ==Graph Convolutional Networks (GCN)==
- Differences from SDNE and DNGR
- SDNE and DNGR takes as input the global neighborhood of each node and this can be computationally expensive and inoptimal
- Method: defines a convolution operator on graph
- The model iteratively aggregates the embeddings of neighbors for a node
- The model uses a function of the obtained embedding and its embedding at previous iteration to obtain the new embedding
- Advantages
- Aggregating embedding of only local neighborhood makes it scalable and multiple iterations allows the learned embedding of a node to characterize global neighborhood.
- Filters
- Spatial filters: operate directly on the original graph and adjacency matrix
- Spectral filter: operate on the spectrum of graph-Laplacian
- Differences from SDNE and DNGR
- Variational Graph Auto-Encoders (VGAE)
Other Methods
- ==LINE==
- Defines two functions and minimizes the combination of the two
- First-order proximities
-
Aim to keep the adjacency metric and dot product of embedding close
-
LINE defines two joint probability distributions for each pair of vertices, one using adjancency matrix and the other using the embedding.
- Then, LINE minimizes the Kullback-Leibler (KL) divergence of these two distributions
-
-
Second-order proximities
- It’s similar to the first-order proximities
- First-order proximities
- Defines two functions and minimizes the combination of the two
Discussion
- Different methods have their pros and cons.
Applications
- Network Compression
- Visualization
- Clustering
- Link Prediction
- Node Classification
Experimental Setup
Datasets
Evaluation Metrics
Experiments and Analysis
Deep Learning methods: Representation Learning on Graphs: Methods and Applications
Node2Vec
DeepWalk: Online Learning of Social Representations (KDD2014)
- There is a good Chinese blog.
LINE: Large-scale Information Network Embedding (WWW2015)
- There is a good Chinese blog.
GCN
There is a blog about GRAPH CONVOLUTIONAL NETWORKS.
Modeling Relational Data with Graph Convolutional Networks
Semi-Supervised Classification with Graph Convolutional Networks (ICLR2017)
Knowledge graph reasoning/completion
-
Path-based: ProPPR
- Embedding-based
- Rule+embedding:
- differentiable proving: End-to-End Differentiable Proving
Text+graph jointly embedding
Representing Text for Joint Embedding of Text and Knowledge Bases
- Paper link: http://www.aclweb.org/anthology/D15-1174
- Paper summary: They propose a model that captures the compositional structure of textual relations and jointly optimizes entity, knowledge base, and textual relation representations.
- They model sub-structure of text and share parameters among related dependency paths, using a unified loss function learning entity and relation representations to maximize performance on the knowledge base link prediction task.
Introduction
- Motivation: Even though there are some impressively large existing knowledge bases, they are still far from complete. This has motivated research in automatically deriving new facts to extend a manually built knowledge base, by using information from the existing knowledge base, textual mentions of entities, and semi-structured data such as tables and web forms.
- Prior work:
- Method: every textual relation receives its own continuous representation, learned from the pattern of its co-occurrences in the knowledge graph.
- Disadvantage: largely synonymous textual relations often share common sub-structure, and are composed of similar words and dependency arcs.
Related Work
Knowledge base completion
- A review of relational machine learning for knowledge graphs: From multi-relational link prediction to automated knowledge graph construction.
- a broad overview of machine learning models for knowledge graphs
- Embedding entities and relations for learning and inference in knowledge bases.
- a simple variant of a bilinear model DISTMULT outperformed TransE
Relation extraction using distant supervision
- Distant supervision for relation extraction without labeled data.
- demonstrated that both surface context and dependency path context were helpful for the task
- Disadvantage: did not model the compositional sub-structure of this context
- Other work proposed more sophisticated models that reason about sentence-level hidden variables (Riedel et al., 2010; Hoffmann et al., 2011; Surdeanu et al., 2012) or model the noise arising from the incompleteness of knowledge bases and text collections (Ritter et al., 2013), inter alia.
Combining knowledge base and text information
- Reading the web with learned syntactic-semantic inference rules.
- A combination of knowledge base and textual information was first shown to outperform either source alone in the framework of path-ranking algorithms in a combined knowledge base and text graph
- Compositional vector space models for knowledge base completion.
- Learn co-occurrence based textual relation representations
- Knowledge graph and text jointly embedding.
- combined knowledge base and text information by embedding knowledge base entities and the words in their names in the same vector space
- Disadvantage: did not model the textual co-occurrences of entity pairs and the expressed textual relations.
- Connecting language and knowledge bases with embedding models for relation extraction.
- combined continuous representations from a knowledge base and textual mentions for prediction of new relations
- Disadvantage: The two representations were trained independently of each other and using different loss functions, and were only combined at inference time. Additionally, the employed representations of text were non-compositional.
Continuous representations for supervised relation extraction
- Sentence-level relation extraction
- Relation classification via convolutional deep neural network.
- Improved relation extraction with feature-rich compositional embedding models.
- Improved semantic representations from tree-structured long short-term memory networks.
- Convolutional neural networks for sentence classification.
Models for knowledge base completion
Definitions
- Knowledge bases: RDF triples, in the form (subject, predicate, object)
- For brevity, we will denote triples by $(e_s, r, e_o)$
- Task
- Given a training KB consisting of entities with some relations between them, to predict new relations (links) that do not appear in the training KB.
- Formal definition: build models that rank candidate entities for given queries $(e_s, r, ?)$ or $(?, r, e_o)$, which ask about the object or subject of a given relation.
- Incorporate textual information
- represent both textual and knowledge base relations in a single graph of “universal” relations
- The textual relations are represented as full lexicalized dependency paths
- We can add this relation to the knowledge graph based on this sentential occurrence, then we can get a KG additionally containing textual relations
- Notation
- ε the set of entities R the set of relation types T $(e_s, r, e_o)$, and its presence $y_T \in {0, 1}$ $f(e_s, r, e_o)$ represent the model’s confidence in the existence of the triple
Basic Models
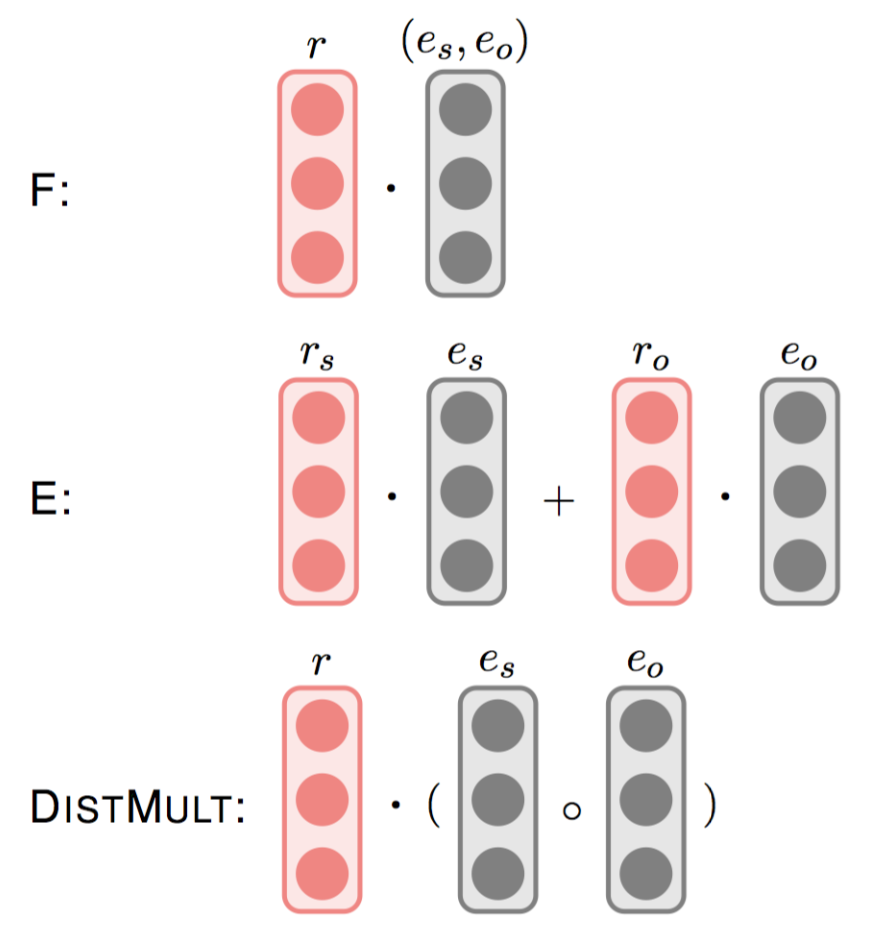
- Model F and E
- Paper: Relation extraction with matrix factorization and universal schemas
- They were used for a combined KB+text graph
- Model F
- K-dimensional latent feature vector for $(e_s, e_o)$ and K-dimensional $r$
- $f(e_s, r, e_o)=v(r)^T v(e_s, e_o)$
- Model E
- Goal: capture the compatibility between entities and the subject and object positions of relations
- For each relation type r, the model learns two latent feature vectors $v(r_s)$ and $v(r_o)$ of dimension K. For each entity (node) $e_i$, the model also learns a latent feature vector of the same dimensionality.
- $f(e_s, r, e_o)=v(r_s)^Tv(e_s)+ v(r_o)^Tv(e_o)$
- DISTMULT
- Paper: Embedding entities and relations for learning and inference in knowledge bases
- Originally used for a KG containing only KB relations
- each entity $e_i$ and each relation r is assigned a latent feature vector of dimension K
- $f(e_s, r, e_o)=v(r)^T\bigg(v(e_s) \circ v(e_o)\bigg)$
- $\circ$ : element-wise vector product
- Summary
- knowledge base and textual relations are treated uniformly, and each textual relation receives its own latent representation of dimensionality K.
- queries $(e_s, r, ?)$ are answered by scoring functions looking only at the entity and KB relation representations, without using representations of textual mentions
CONV: Compositional Representations of Textual Relations

- Method: Use a convolutional neural network applied to the lexicalized dependency paths treated as a sequence of words and dependency arcs with direction.
- Architecture: Word embedding -> convolutional network -> max pooling
Training loss function
-
To improve efficiency
- For $e’$, use negative sample: sample $\text{Neg}(e_s, r, ?)$
- For $e_o$, limit the candidate entities to ones that have types consistent with the position in the relation triple
-
For textual relations
- A weighting factor $\tau$ for the loss on predicting the arguments of textual relations
-
Let $\mathcal{T}{\text{KB}}$ and $\mathcal{T}{\text{text}}$ represent the set of knowledge base triples and textual relation triples respectively.
-
Final loss
- Where $\lambda$ is the regularization parameter and $\tau$ is the weighing factor of the textual relations
Experiments
Dataset and Evaluation Protocol
- FB15k-237
- subset of FB15k
- excludes redundant relations and direct training links for held-out triples
Implementation details
Experimental results
Hyperparameter Sensitivity
Reinforcement Learning Query Answering
DeepPath: A Reinforcement Learning Method for Knowledge Graph Reasoning
Go for a Walk and Arrive at the Answer: Reasoning Over Paths in Knowledge Bases using Reinforcement Learning (Reading Group Presentation)
- Paper link: https://arxiv.org/abs/1711.05851
Paper Summary
- Background: Knowledge bases are often incomplete – many facts can be inferred from the KB by synthesizing existing information.
- Idea: A neural reinforcement learning approach which learns how to navigate the graph conditioned on the input query to find predictive paths
Introduction
- Reinforcement learning
- Task definition
- Given a massive knowledge graph, we learn a policy, which, given the query (entity1,relation,?), starts from entity1 and learns to walk to the answer node by choosing to take a labeled relation edge at each step, conditioning on the query relation and entire path history. This formulates the query-answering task as a reinforcement learning (RL) problem where the goal is to take an optimal sequence of decisions (choices of relation edges) to maximize the expected reward (reaching the correct answer node).
- Advantages
- take paths of variable length
- no pretraining and trains on KG from scratch with RL
- computationally efficient
- only search in a small neiborhood around the query entity
- the reasoning paths form an interpretable explaination for its prediction
Task and Model
- Formal definition of query answering in a KB
- ε the set of entities R the set of binary relations KB a collection of facts stored as triplets (e1, r, e2) and e1,e2 ∈ ε, r ∈ R Query answering seeks to answer questions of the form (e1, r, ?) Fact prediction is predicting if a fact is true or not (e1, r, e2)?
- Environment - States, Actions, Transitions and Rewards
- KG = (V,E,R)
- e1,e2 are represented as the nodes and relation r as labeled edge
- V = ε, E ⊆ V✖️R✖️V, we add inverse relation of every edge, undo a potentially wrong decision
- Markov decision process (S, O, A, δ, R)
- States (et, e1q, rq, e2q)
- et: current location of exploration node of the entity
- query (e1q, rq), answer (e2q)
- Observations O(s=(et, e1q, rq, e2q)) = (et, e1q, rq) Actions A(s=(et, e1q, rq, e2q)) = (et, r, v) and (et, NO-OP, et) Transition δ(S, A) = (v, e1q, rq, e2q) Reward St = (et, e1q, rq, e2q), et = e2q, then reward = 1, else = 0
- States (et, e1q, rq, e2q)
- KG = (V,E,R)
- Policy Network
- Use LSTM to learn the randomized history-dependent policy.
- Training
Bioinformation
Relation extraction for biological pathway construction using node2vec
- Data collection
- PubMed XML records were retrieved using EFetch API
- PMIDs, titles, and abstracts were extracted from the XML records
- use the keyword ‘type 2 diabetes’ to retrieve all papers indexed with this search term. Only articles including the term in the titles and abstracts were collected.
- preprocessed for entity and relationship extraction.
- Entity and relation extraction
- Entity extraction: PKDE4J (entity) + Stanford NER model (biological entities)
- Relationship extraction: A co-occurrence network
- Node2vec for latent path prediction
- Performance evaluation