- Sequence Labeling
- Language Modeling (generative models)
- On the State of the Art of Evaluation in Neural Language Models (ARXIV2017)
- Exploring the Limits of Language Modeling (Google AI2016)
- Tying Word Vectors and Word Classifiers: A Loss Framework for Language Modeling (ARXIV2016)
- Using the Output Embedding to Improve Language Models (ARXIV2016)
- Character-aware Neural Language Model (AAAI 2016)
- Deep contextualized word representations (NAACL 2018)
I will be a research assistant under the guidance of Prof.Xiang Ren at USC next term, hence I’m reading some related papers and taking some notes for preparation.
Since my previous research area is Natural Language Processing, I may concentrate my research more on Sequence Labeling and Language Modeling.
Sequence Labeling
Supervised Sequence Labelling with RNN
- This is a summary paper written by Alex Graves. Instead of calling it as paper, it’s more like a book actually.
- Structure of the book:
- Chapter 2: briefly reviews supervised learning in general, and pattern classification in particular.
- Chapter 3: backgroud material for feedforward and RNN, with emphasis on their application to labelling and classification tasks.
- Chapter 4: describe the LSTM architecture and introduce bidirectional LSTM.
- Chapter 5: an experimental comparison of BLSTM to other neural network architectures.
- Chapter 6: the use of LSTM in hidden Markov model-neural network hybrids.
- Chapter 7: introduces connectionist temporal classification
- Chapter 8: covers multidimensional networks
- Chapter 9: hierarchical subsampling networks
- This book can serve as a reference book.
End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF (ACL2016)
Background
- Traditional Linear Statistical models (e.g. HMM and CRF)
- Drawback: rely heavily on hand-crafted features and task-specific resources, however task-specific knowledge is costly to develop, making Sequence Labeling difficult to adapt to new tasks or new domains
- Non-liner Neural Network models
- usage of word embedding and RNN, LSTM, GRU shown great success in modeling sequential data
For sequence labeling (or general structured prediction) tasks, it is beneficial to consider the correlations between labels in neighborhoods and jointly decode the best chain of labels for a given input sentence. For example, in POS tagging an adjective is more likely to be followed by a noun than a verb, and in NER with standard BIO2 annotation I-ORG cannot follow I-PER. Therefore, we model label sequence jointly using a conditional random field (CRF), instead of decoding each label independently.
Task
- Seauence labeling tasks (e.g. POS tagging and NER)
Related work
- BLSTM-CRF by Huang (2015)
- BLSTM for word-level representations and CRF for jointly label decoding
- Differences with this paper:
- did not employ CNNs
- combined NN model with hand-crafted features
- LSTM-CNNs by Chiu and Nichols (2015)
- CNNs for character- and BLSTM for word-level representations
- Differences with this paper:
- this paper use CRF for joint decoding
- it utilizes external knowledge and data-preprocessing
- BLSTM-CRF by Lample (2016)
- utilized BLSTM to model both character and word-level information and contained data pre-processing
- Differences with this paper:
- This paper use CNN to model character-level information
- RNN-CNNs model
- CharWNN architecture
Contributions
- End-to-end model requiring no task-specific resources, feature engineering or data pre-processing
- easily applied to a wide range of sequence labeling tasks
- State-of-the-art performance
Proposed model and key idea
- CNN-BLSTM-CRF
- use CNN to compute the character-level representation for each word, then concatenate the character-level representation with the word embedding to feed into BLSTM, finally feed the output of BLSTM to CRF layer to jointly decode the best label sequence.
- The main architecture is like this:
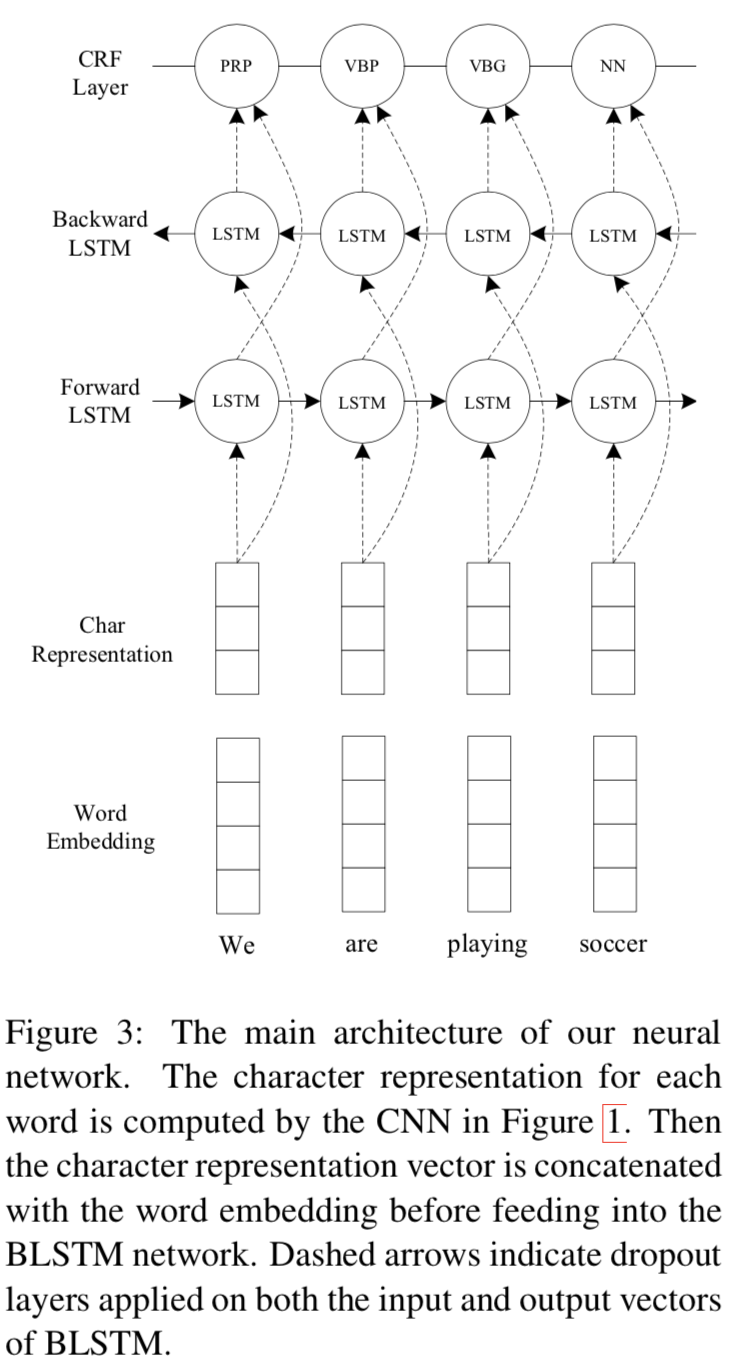
Experiment setup
Dataset with detailed information
- Penn Treebank WSJ corpus for POS tagging
- CoNLL 2003 corpus for NER
Neural architectures for named entity recognition (NAACL2016)
Background
- Challenge of NER
- only a small amount of supervised training data
- few constraints on the kind of words
- Traditional method
- use constructed orthographic features and language-specific knowledge resources
Related work
- CNN-CRF by Collobert (2011)
- Use CNN over a sequence of word embeddings with a CRF layer on top
- Differences with this paper:
- Without character-level embeddings
- Replace this papers’ LSTM by CNN
- LSTM-CRF by Huang (2015)
- Differences with this paper:
- combined NN model with hand-crafted features
- Differences with this paper:
Gillick et al. (2015) model the task of sequence labeling as a sequence to sequence learning problem and incorporate character-based representations into their encoder model.
Zhou and Xu (2015) also used a similar model and adapted it to the semantic role labeling task. Lin and Wu (2009) used a linear chain CRF with L2 regularization, they added phrase cluster features extracted from the web data and spelling features. Passos et al. (2014) also used a linear chain CRF with spelling features and gazetteers.
Contributions
- Neural architectures that use no language-specific resources or features, did not perform any dataset preprocessing
- Capable of capturing two intuitions
- Best performance ever
Proposed model and key idea
- BLSTM-CRF
- The main architecture is like this:
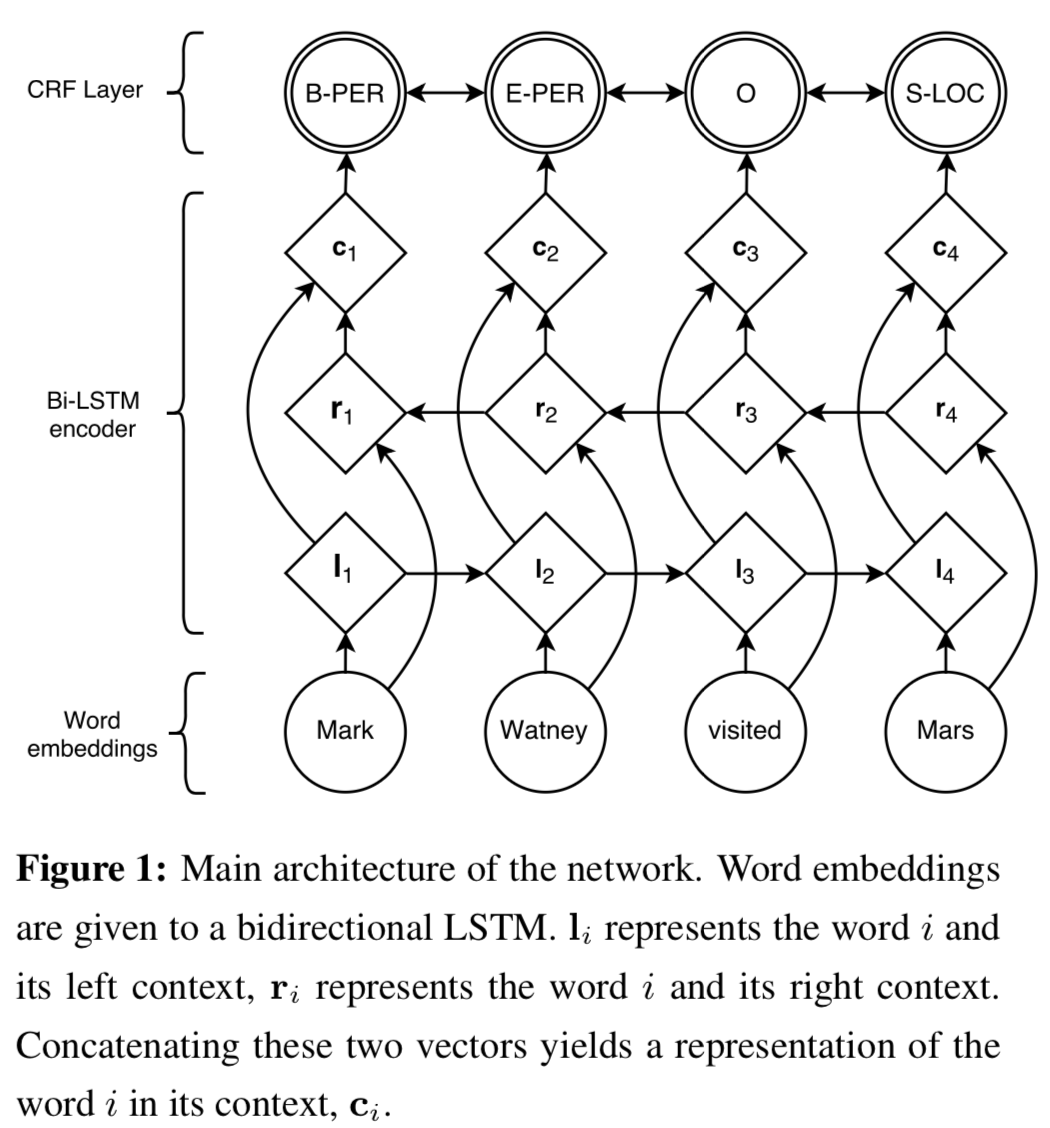
- The main architecture is like this:
- Transition-Based Chunking Model
- labels a sequence of inputs using an algorithm similar to transition-based dependency parsing
- Advantage: directly constructs representations of the multi-token names
- Use both pre-trained word representations and “character-based” representations
Experiment setup
Dataset with detailed information
- CoNLL-2002 and CoNLL-2003 that contain independent named entity labels for English, Spanish, German and Dutch
- Four types of named entities: locations, persons, organizations and others
Empower Sequence Labeling with Task-Aware Neural Language Model (AAAI2018)
Background
- Challenge of NN
- Overwhelming number of parameters in NNs and relatively small size of most sequence labeling corpus
- Annotations alone may not be sufficient to train complicated models, so we need extra knowledge
Contributions
- Does not relay on any additional supervision
- Efficiency: training completes in about 6 hours on a single GPU without using any extra annotations
- Much efficiency without loss of effectiveness
Proposed model and key idea
-
LM-LSTM-CRF
- Leverage both word-level and character-level knowledge
- Employ high-way networks to transform the output of character-level layers into different semantic spaces
- Fine-tune pre-trained word embedding instead of co-training or pre-training the whole word-level layers

-
Something special
- In order to mediate and unify language modeling and sequence labeling, the authors use highway layers to conduce nonlinear transformation
Experiment setup
Dataset with detailed information
- CoNLL 2003 NER and CoNLL 2000 chunking task
- WSJ portion of the Penn Treebank POS tagging task
Nice blog on NER
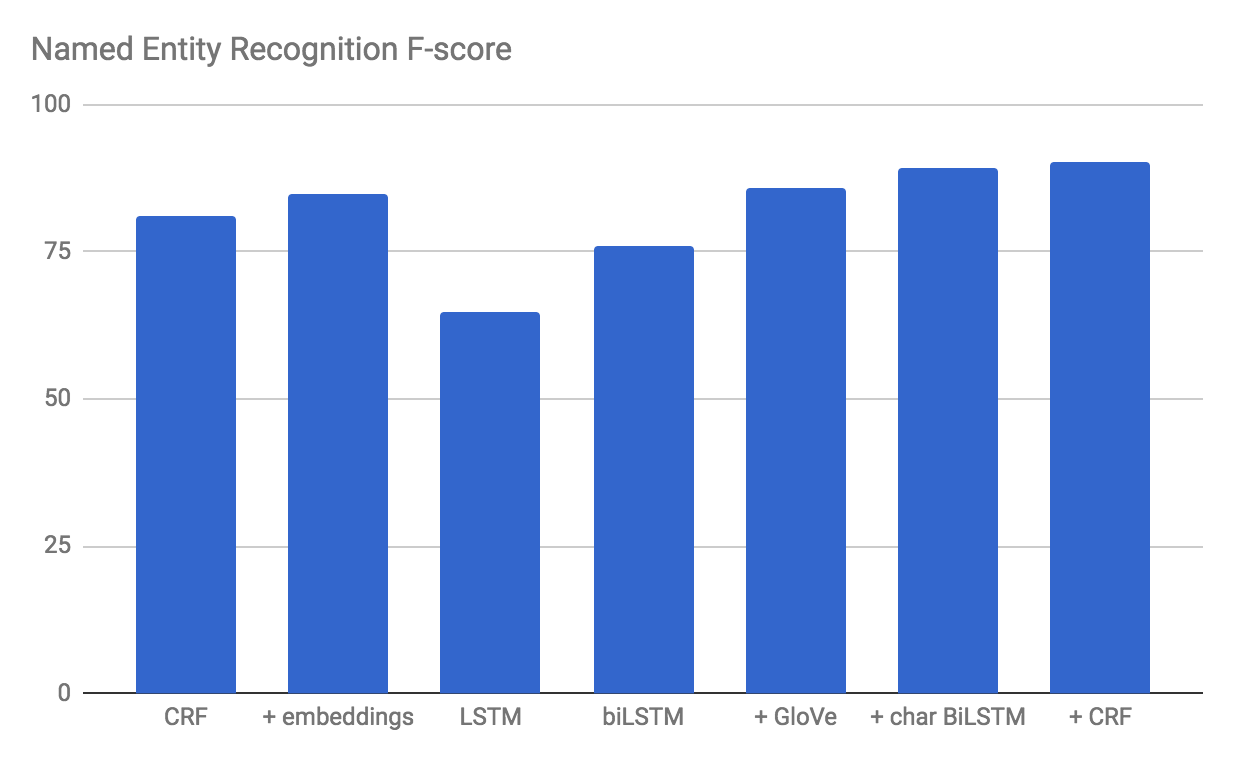
One of the most well-known weaknesses of the previous generation of NLP models is that they are unable to model semantic similarity between two words. For all our CRF knows, Paris and London differ as much in meaning as Paris and cat. To overcome this problem, many CRFs for Named Entity Recognition rely on gazetteers — lists with names of people, locations and organizations that are known in advance. This is a suboptimal solution, however: gazetteers are inherently limited and can be costly to develop. Also, they’re usually only available for the named entities themselves, so that the semantic similarity between other words in their context goes unn oticed. This is whe re it can pay off to take the first step on the path to deep learning.
BiLSTMs process the data with two separate LSTM layers. One of them reads the sentence from left to right, while the other one receives a reversed copy of the sentence to read it from right to left. Both layers produce an output vector for every single word, and these two output vectors are concatenated to a single vector that now models both the right and the left context.
To combat this data sparsity, it is common to initialize the embedding layer in a neural network with word embeddings that were trained on another, much larger corpus.
Many entities share informative suffixes, such as the frequent -land or -stan for country names. Because it treats all tokens as atomic entities, our neural network currently has no access to this type of information. This blindness has given rise to the recent popularity of character-based models in NLP.
A final disadvantage of the current method that we’ll discuss here, is that it predicts all labels independently of each other: as it labels a word in a sentence, it does not take into account the labels it predicts for the surrounding words. As Huang et al. (2016) suggest, we can solve this problem by adding a Conditional Random Field layer to our network.
Language Modeling (generative models)
On the State of the Art of Evaluation in Neural Language Models (ARXIV2017)
Exploring the Limits of Language Modeling (Google AI2016)
Tying Word Vectors and Word Classifiers: A Loss Framework for Language Modeling (ARXIV2016)
Using the Output Embedding to Improve Language Models (ARXIV2016)
Character-aware Neural Language Model (AAAI 2016)
Code: Github, in lua language
Reference: Paper Note from CSDN
Background
- Definition
- A probability distribution over a sequence of strings (words)
- Traditional count-based n-gram Language Model
- making an n-th order Markov assumption and estimating n-gram probabilities via counting and subsequent smoothing
- Drawback: probabilities of rare n-grams can be poorly estimated due to data sparsity
- Neural Network models (NLM)
- usage of word embedding and RNN, LSTM, GRU shown great success in modeling sequential data
- Drawback: blind to subword information
Task
- Language modeling tasks
Related work
- FNLM by Bilmes and Kirchhoff (2006)
- Goal: address the rare word problem
- Methods: represent a word as a set of shared factor embeddings
- Advantage: can incorporate morphemes, word shape information (e.g. capitalization) or any other annotation (e.g. part-of-speech tags) to represent words.
Contributions
- leverages subword information through a character-level convolutional neural network (CNN), whose output is used as an input to a recurrent neural network language model (RNN-LM)
- utilizes only character-level inputs, don’t utilize word/morpheme embeddings in the input layer
- Fewer parameters, small model size, better results
Proposed model and key idea
- CNN-LSTM-LM
- use CNN to compute the character-level representation for each word.
- A max-over-time pooling operation is applied to obtain a fixed-dimensional representation of the word, which is given to the highway network.
- The highway network’s output is used as the input to a multi-layer LSTM.
- Finally, an affine transformation followed by a softmax is applied over the hidden representation of the LSTM to obtain the distribution over the next word.
- The main architecture is like this:

Experiment setup
Dataset with detailed information
- Penn Treebank (PTB) for POS tagging
Deep contextualized word representations (NAACL 2018)
API: AllenNLP
Code: tensorflow version
Download pertained models: Official site
Reference: Official site
Background
- Word representations
- On ideally condition, they should model
- complex characteristics of word use (e.g., syntax and semantics)
- how these uses vary across linguistic contexts (i.e., to model polysemy)
- On ideally condition, they should model
- Traditional word type embedding
- Word vectors/Glove
- Drawback: only allows a single context-independent representation for each word
- ELMo (Embeddings from Language Models)
- word vectors are learned functions of the internal states of a deep bidirectional language model (biLM), which is pre-trained on a large text corpus
- Effective and simple
Task
- Word representations
Related work
Contributions
Proposed model and key idea
- ELMo
Experiment setup
Dataset with detailed information
- Question answering
- Textual entailment
- Semantic role labeling
- Coreference resolution
- Named entity extraction
- Sentiment analysis