- Project Sets
- Paper Note
- PROGRAMMING DETAIL
This is a note about implementing the final project of my Artificial Intelligence course. The scope of this project is develop an AI agent for Gomoku.
Gomoku, also know as five-in-a-row, is a strategy board game which is traditionally played with Go pieces on a go board with 15 × 15 intersections. The rules for Gomoku are similar to Go, where two players place stones alternatively on the intersections of the board. The winner is the first player to get 5 of their stones in a row, either vertically, horizontally or diagonally.
Project Sets
Rules
- Gomoku Rule: Free Gomoku Rule(five or more)
- Free-style gomoku requires a row of five or more stones for a win.
- In any size of a board, freestyle gomoku is an m,n,k-game, and it is known that the second player does not win. With perfect play, either the first player wins or the result is a draw.
-
Balanced opening from a set: AI and us has the same opportunity to be the first player.
-
The board has 20x20 squares
-
15 seconds per move, 90 seconds per match for maximum
-
10 fixed AI, 12 matches with each one
Restrictions
- No more than 3 people a team
- Upload to test once a day
- Uploading file may not take more than 5 MB of space (zipped together with all necessary files) named as id.zip
- Only one CPU core
- No deep neural network (shallow is okay but needs to be less than 5 MB)
Paper Note
CS221 Project Final Report Gomoku Game Agent
Source Code: Github here
Methods
Take away message
- Tree search based approach with alpha beta pruning implemented
- focus on developing good heuristic functions which are mainly inspired by human players strategy as evaluation function to speed up the computation
Main idea to obtain an optimal agent
- Extract more features by expert knowledge
- Leverage advanced regularization skills for temporal difference (TD)-Learning
ADP with MCTS Algorithm for Gomoku
Methods
Take away message
- We combine a shallow neural network, which is trained by Adaptive Dynamic Programming (ADP), with Monte Carlo Tree Search (MCTS) algorithm for Gomoku.
- MCTS algorithm is based on Monte Carlo simulation method, which goes through lots of simulations and generates a game search tree.
- The ADP and MCTS methods are used to estimate the winning rates respectively. We weight the two winning rates to select the action position with the maximum one.
Game Tree search
- Based on the min-max tree combined with a evaluation function of leaf board situations
- Use alpha-beta pruning to speed up the game tree search
- Defect
- Static evaluation function always requires complicated artificial design and it needs a lot of time to consider plenty of situations
- It can not learn anything while playing Gomoku. It just obeys the rule which is made before, and could not be improved by playing.
- Time and space complexity growing exponentially with search depth
Adaptive Dynamic Programming (ADP)
- Core idea: The action decision or the value function can also be described in a continuous form, approximated by a nonlinear function in neural networks.
- Structure:
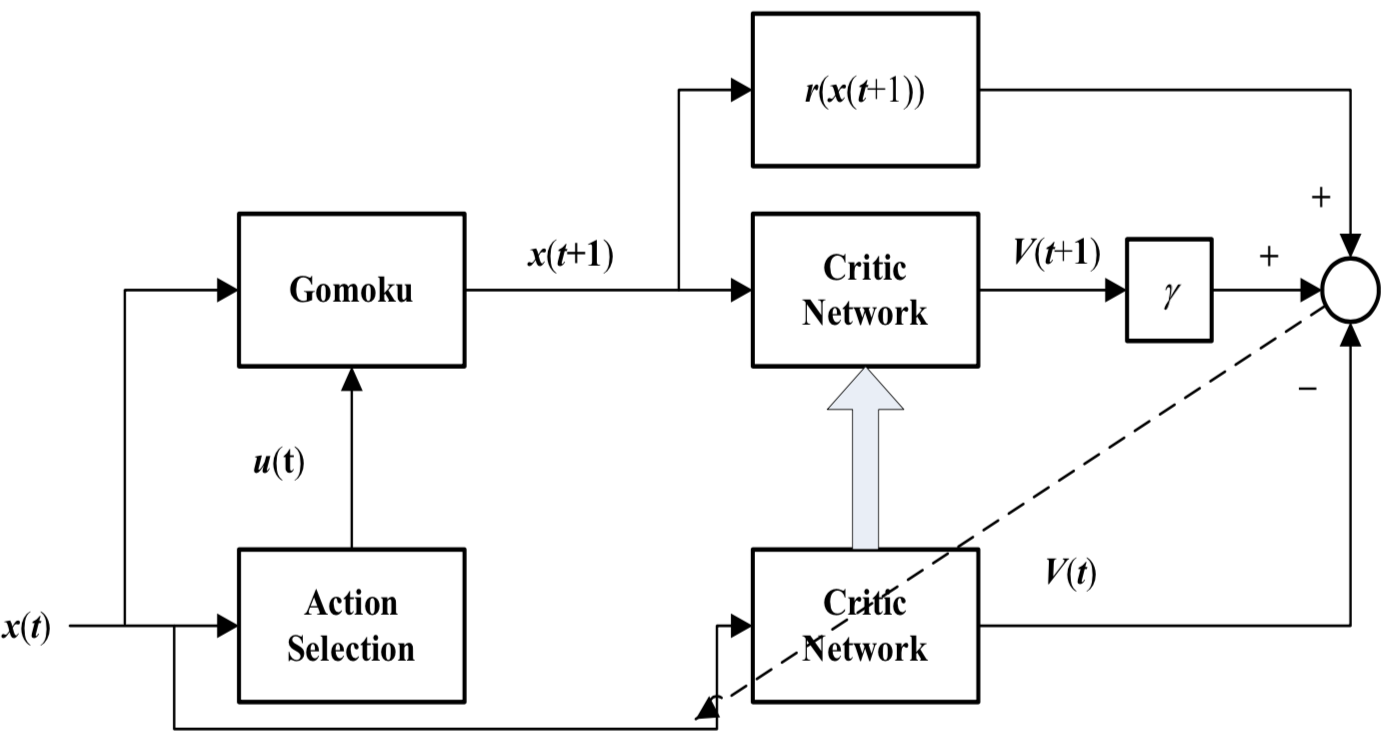
- Defect
- Only effective for those games with available expert knowledge because its input was designed by pre-determined pattern
- Also, it has a short-sighted defect for neural network evaluation function.
Monte Carlo Tree Search (MCTS)
- Core idea: Taking random simulations in the decision space and building a search tree according to the results.
- Four stage:
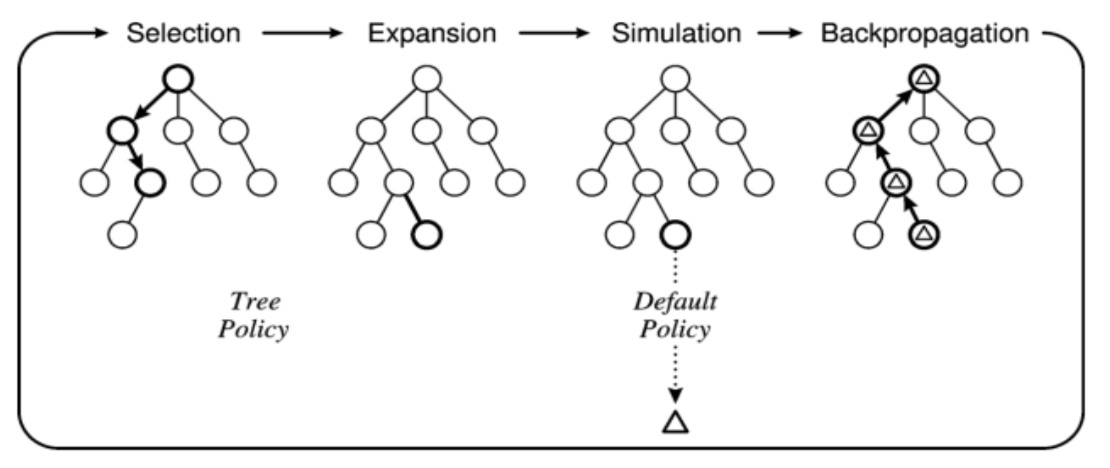
- Selection: Begins from the root node, and recursively applies the child selection policy (also known as Tree Policy) to descend through the tree until it reaches the most urgent expandable node.
- Expansion: Add one or more child nodes to expand the tree
- Simulation: Run a simulation from the leaf node based on the settled policy (or called Default Policy) to produce an outcome
- Backpropagation: Back propagate the simulation result through the selected nodes to update their state values.
- Defect
- needs some complex domain knowledge additionally
- must spend lots of time in simulation to get a satisfactory result
ADP-MCTS
- Process
- Obtain 5 candidate moves and their winning probabilities from the neural network which is trained by ADP. We call them ADP winning probabilities.
- The 5 candidate moves and their situations of board are seen as the root node of MCTS. Then, we obtain 5 winning probabilities respectively from MCTS method. We call them MCTS winning probabilities.
- To get a more accurate prediction of winning probability, we calculate the weighted sum of ADP and its corresponding winning probability of MCTS: $w_p=\lambda w_1 + (1-\lambda)w_2$
- Advantage
- Save time: the candidate moves obtained from ADP make the MCTS’s search space smaller than before
Effective Monte-Carlo Tree Search Strategies for Gomoku AI
Methods
Take away message
- Combined with progressive strategies used in Go program MANGO but uses different heuristic knowledge and roll-out policy
PROGRAMMING DETAIL
Environment Setup
- Python code templates: pbrain pyrandom
- Include installing some python package
- Description of how to use
.pyto generate your own AI
- Download Gomocup Manager
- It allows you to play against Gomocup AIs
- Download some AI
Source code
- Edit
example.pyto design your own AI, and strategies are written in functionbrain_turn()
Reference
- Gomocup AI source code templates
- Download Gomoku programs included source code
- Mainly written in C and C++
- Here is a brief repo
- Documents how to program Gomoku program
- More like papers and doesn’t mention implementing details